 数据结构笔记(2)
数据结构笔记(2)
动图演示:
VISU算法 https://visualgo.net/zh/
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
下面图片地址:https://blog.csdn.net/ityqing/article/details/82838524
2
3
4
5
# 四、哈希表
详细资料(示例用法):https://python-data-structures-and-algorithms.readthedocs.io/zh/latest/07_%E5%93%88%E5%B8%8C%E8%A1%A8/hashtable/
哈希表是一个通过哈希函数来计算数据存储位置的数据结构,通常支持如下操作:
insert(key,value):插入键值对(key,vlaue)
get(key):如果存在键为key的键值对,则返回其value,否则返回空值
delete(key):删除键为key的键值对
哈希表由一个直接寻址表和一个哈希函数组成。
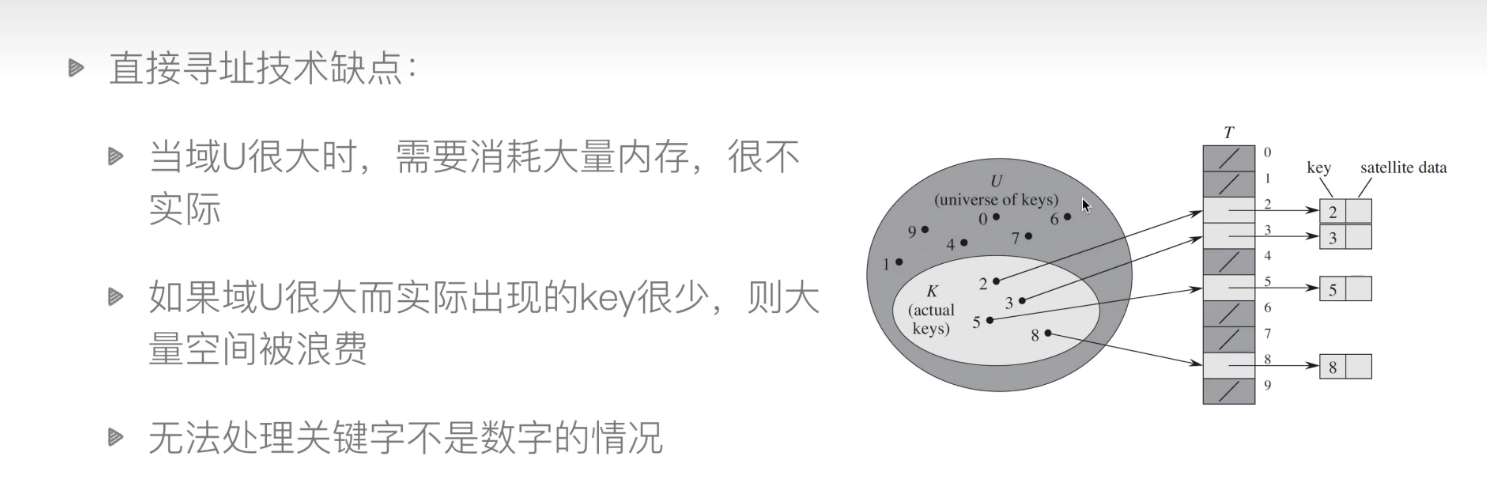
# 1.1 直接寻址表
当关键字的全域U比较小时,直接寻址是一种简单而有效的方法。
- 直接寻址表:key为k的元素放到k位置上
- 改进直接寻址表:哈希(Hashing)
- 构建大小为m的寻址表T
- key为k的元素放到h(k)位置上
- h(k)是一个函数,其将域U映射到表T【0,1...m-1】
# 1.2 常见哈希函数
除法哈希法(取余):
- h(k)= k % m
乘法哈希法:
- h(k) = floor(m 乘(A 乘 key % 1))
全域哈希法:

# 1.3 哈希表
哈希表(Hash Table,又称为散列表),是一种线性表的存储结构。哈希表由一个直接寻址表和一个哈希函数组成。哈希函数h(k)将元素关键字k作为自变量,返回元素的存储下标。
通过一个哈希函数来计算一个元素应该放在数组哪个位置,当然对于一个 特定的元素,哈希函数每次计算的下标必须要一样才可以,而且范围不能超过给定的数组长度。
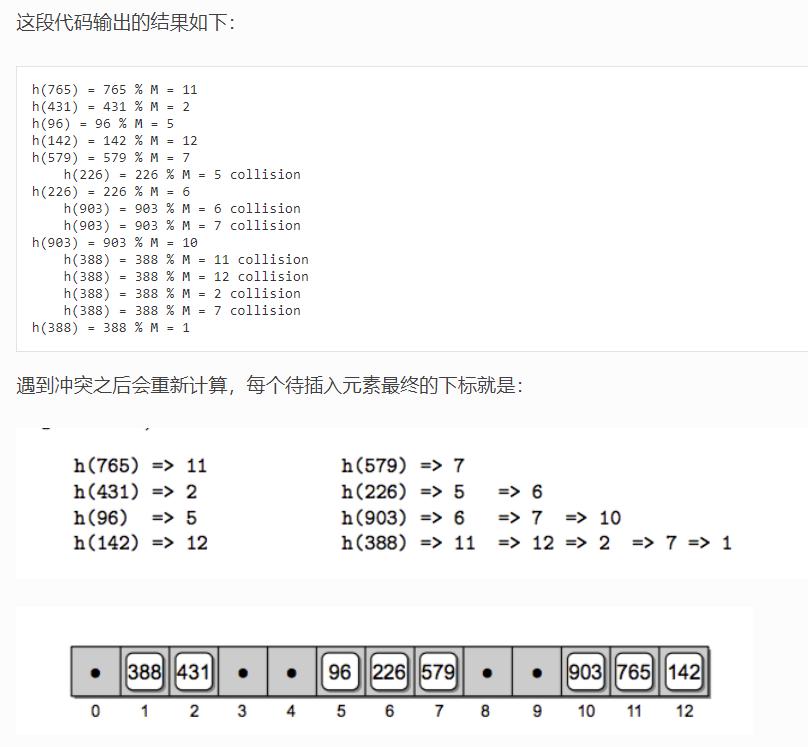
假如我们有一个数组 T,包含 M=13 个元素,我们可以定义一个简单的哈希函数 h
h(key) = key % M
这里取模运算使得 h(key) 的结果不会超过数组的长度下标。我们来分别插入以下元素:
765, 431, 96, 142, 579, 226, 903, 388
先来计算下它们应用哈希函数后的结果:取余运算,将取好的模插入到开辟好的数组下标中,
M = 13
h(765) = 765 % M = 11
h(431) = 431 % M = 2
h(96) = 96 % M = 5
h(142) = 142 % M = 12
h(579) = 579 % M = 7
h(226) = 226 % M = 5
h(903) = 903 % M = 6
h(388) = 388 % M = 11
2
3
4
5
6
7
8
9
# 哈希冲突 (collision)

这里到插入 226 这个元素的时候,不幸地发现 h(226) = h(96) = 5,不同的 key 通过我们的哈希函数计算后得到的下标一样, 这种情况成为哈希冲突。当一个位置有多个不同的元素,就叫做哈希冲突
# 1. 解决哈希冲突-开放寻址法
开放寻址法:如果哈希函数返回的位置以及有值,则可以向后探查新的位置来存储这个值
当一个槽被占用的时候,采用一种方式来寻找下一个可用的槽。 (这里槽指的是数组中的一个位置),根据找下一个槽的方式不同,分为:
- **线性探查:**如果上面这个5下标被占用(记做i),则继续向后探查 i+1,i+2,.....
- 当一个槽被占用,找下一个可用的槽 h(k,i)=(h′(k)+i)%m,i=0,1,...,m−1
- **二次探查:**如果位置i被占用,则探查i+1的平方,i-1的平方,i+2的平方,i-2的平方.....
- 当一个槽被占用,以二次方作为偏移量 h(k,i)=(h′(k)+c1+c2i2)%m,i=0,1,...,m−1
- **二度哈希:**有n个哈希函数,当使用第1个函数函数h1发生冲突时,则尝试使用h2,h3....
- 重新计算 hash 结果 h(k,i)=(h1(k)+ih2(k))%m
我们选一个简单的二次探查函数 h(k,i)=(home+i2)%mh(k,i)=(home+i2)%m,它的意思是如果 遇到了冲突,我们就在原始计算的位置不断加上 i 的平方。我写了段代码来模拟整个计算下标的过程:
inserted_index_set = set()
M = 13
def h(key, M=13):
return key % M
to_insert = [765, 431, 96, 142, 579, 226, 903, 388]
for number in to_insert:
index = h(number)
first_index = index
i = 1
while index in inserted_index_set: # 如果计算发现已经占用,继续计算得到下一个可用槽的位置
print('\th({number}) = {number} % M = {index} collision'.format(number=number, index=index))
index = (first_index + i*i) % M # 根据二次方探查的公式重新计算下一个需要插入的位置
i += 1
else:
print('h({number}) = {number} % M = {index}'.format(number=number, index=index))
inserted_index_set.add(index)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 2. 解决哈希冲突-拉链法
哈希表每个位置都连接一个链表,当冲突发生时,冲突的元素将被加到改位置链表的最后
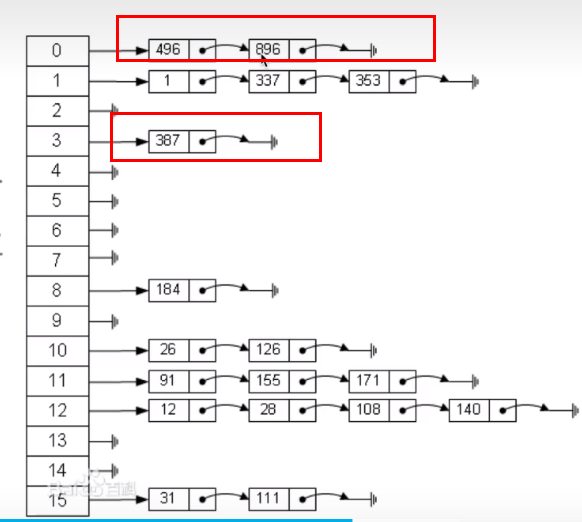
缺点
这样就用链表解决了冲突问题,但是如果哈希函数选不好的话,可能就导致冲突太多一个链变得太长,这样查找就不再是 O(1) 的了
"""
拉链法
"""
class LinkList:
"""链表"""
class Node:
"""节点"""
def __init__(self, item=None):
self.item = item
self.next = None
class LinkListIterator:
"""链表迭代器"""
def __init__(self, node):
self.node = node
def __next__(self):
if self.node: # 调用一次next,链表节点向下走一个
current_node = self.node
self.node = current_node.next
return current_node.item
else:
raise StopIteration('没有节点了')
def __iter__(self):
"""返回当前迭代对象"""
return self
def __init__(self, iterable=None):
self.head = None # 链表的头节点和尾节点
self.tail = None
if iterable: # 如果向链表添加一个列表,则直接调用extend一个一个的添加到列表中
self.extend(iterable)
def append(self, element):
"""添加元素到链表,单个元素"""
current_node = LinkList.Node(element) # 新节点
if not self.head: # 如果没有节点则直接赋值到head和tail
self.head = current_node
self.tail = current_node
else:
self.tail.next = current_node
self.tail = current_node
def extend(self, iterable):
"""添加元素到链表,多个元素一个列表"""
for element in iterable:
self.append(element)
def find(self, element):
"""列表中查找元素"""
for node in self:
if node == element:
return True
else:
return False
def __iter__(self):
"""让类支持迭代,这里将迭代交给LinkListIterator类去做"""
return self.LinkListIterator(self.head) # self可以直接调用类中的类方法
def __repr__(self):
"""打印对象"""
return '<<' + ','.join(map(str, self)) + '>>' # 将当前self对象转成字符串打印
"""
lk = LinkList([2, 3]) # 直接添加列表ini中定义
lk.append(1) # 添加单个元素
lk.extend([4, 5, 6]) # 添加多个元素
print(lk.find(5)) # 查找元素是否在对象中
print(lk) # 打印对象
for e in lk: # 类支持迭代
print(e, end=' ')
True
<<2,3,1,4,5,6>>
2 3 1 4 5 6
"""
class HashTable(object):
"""哈希表"""
def __init__(self, size):
"""创建直接寻址表"""
self.size = size # 直接寻址大小
self.T = [LinkList() for _ in range(self.size)] # 给每个列表中创建一个链表
def h(self, k):
"""哈希函数"""
return k % self.size
def insert(self, k):
"""哈希表中插入元素"""
i = self.h(k)
if self.find(k):
print('改存放位置的链表中已有相同的元素')
else:
self.T[i].append(k)
def find(self, k):
"""在哈希表中查找元素是否存在"""
i = self.h(k) # 通过哈希函数计算出存放位置
return self.T[i].find(k) # 找到对应的存放位置了,在通过链表查询
ht = HashTable(10)
ht.insert(1)
ht.insert(11)
ht.insert(2)
ht.insert(21)
print('查找元素是否存在', ht.find(11))
print('打印哈希表', ht.T)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
# 五、树与二叉树
# 1. 树的基础知识
基础知识:https://python-data-structures-and-algorithms.readthedocs.io/zh/latest/14_%E6%A0%91%E4%B8%8E%E4%BA%8C%E5%8F%89%E6%A0%91/tree/#_2
https://juejin.cn/post/7022956327437598733#heading-6
- 树是一种数据结构 比如:目录结构
- 树是一种可以递归定义的数据结构
- 树是由n个节点组成的集合
- 如果n=0,那这是一棵空树;
- 如果n>0,那存在1个节点作为树的根节点,其他节点可以分为m个集合,每个集合本身又是一棵树。
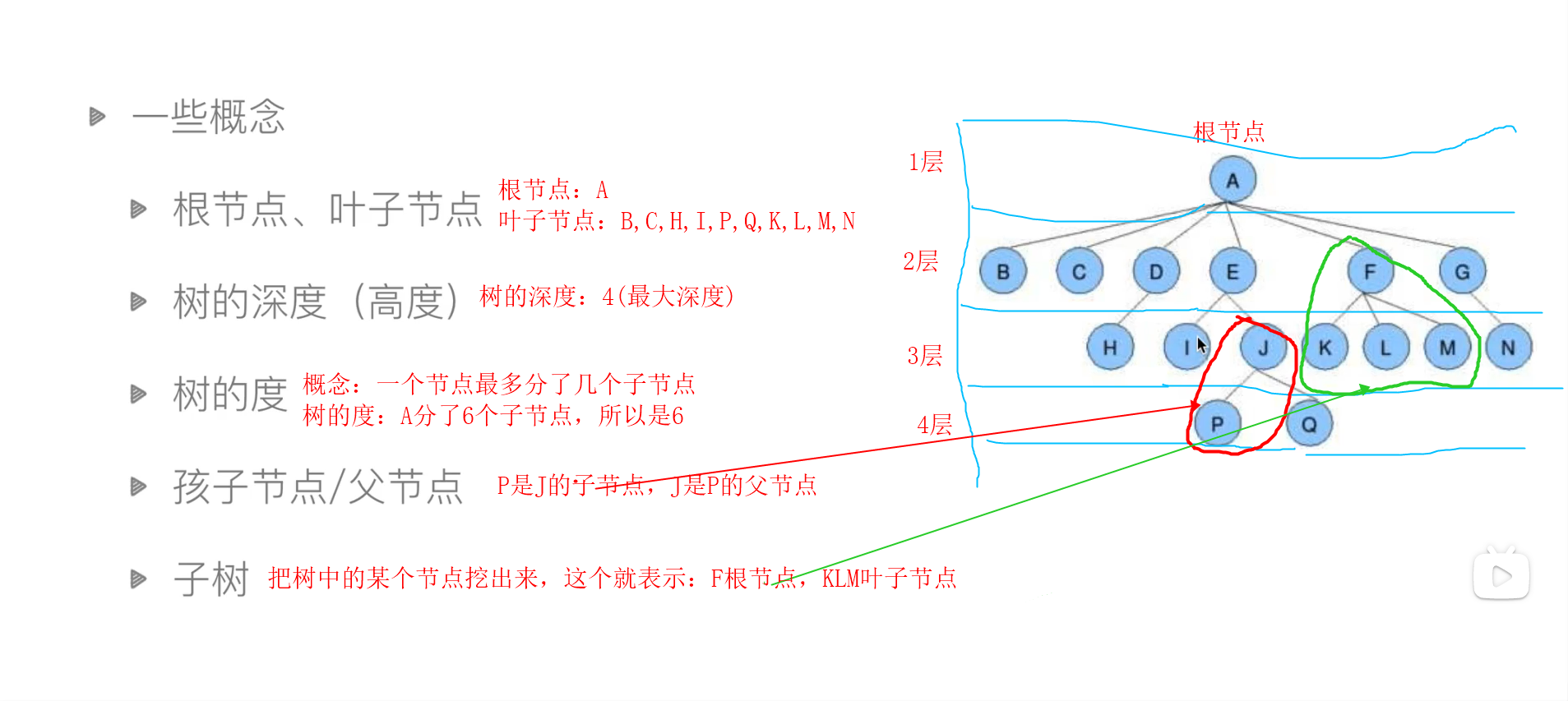
- 一些概念
- 根节点(树的最上面,最根部),叶子节点(树叶,没有分支)
- 树的深度(高度,树有多少层)
- 树的度(表示一个节点,最多分多少个叉[包括根节点])
- 孩子节点(父节点的下面)/父节点(子节点的上面)
- 子树(从这个树的一个节点挖出来就叫子树)
# 1. 树的术语
- 节点的度:一个节点含有的子树的个数称为该节点的度;
- 树的度:一棵树中,最大的节点的度称为树的度;
- 叶节点或终端节点:度为零的节点;
- 父亲节点或父节点:若一个节点含有子节点,则这个节点称为其子节点的父节点;
- 孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;
- 兄弟节点:具有相同父节点的节点互称为兄弟节点;
- 节点的层次:从根开始定义起,根为第1层,根的子节点为第2层,以此类推;
- 树的高度或深度:树中节点的最大层次;
- 堂兄弟节点:父节点在同一层的节点互为堂兄弟;
- 节点的祖先:从根到该节点所经分支上的所有节点;
- 子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
- 森林:由m(m>=0)棵互不相交的树的集合称为森林;
# 2. 树的种类
- 无序树:树中任意节点的子节点之间没有顺序关系,这种树称为无序树,也称为自由树;
- 有序树:树中任意节点的子节点之间有顺序关系,这种树称为有序树;
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
- 完全二叉树:对于一颗二叉树,假设其深度为d(d>1)。除了第d层外,其它各层的节点数目均已达最大值,且第d层所有节点从左向右连续地紧密排列,这样的二叉树被称为完全二叉树,其中满二叉树的定义是所有叶节点都在最底层的完全二叉树;
- 平衡二叉树(AVL树):当且仅当任何节点的两棵子树的高度差不大于1的二叉树;
- 排序二叉树(二叉查找树(英语:Binary Search Tree),也称二叉搜索树、有序二叉树);
- 霍夫曼树(用于信息编码):带权路径最短的二叉树称为哈夫曼树或最优二叉树;
- B树:一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。
- 二叉树:每个节点最多含有两个子树的树称为二叉树;
# 3. 树的存储
https://juejin.cn/post/7022956327437598733
# a. 顺序存储
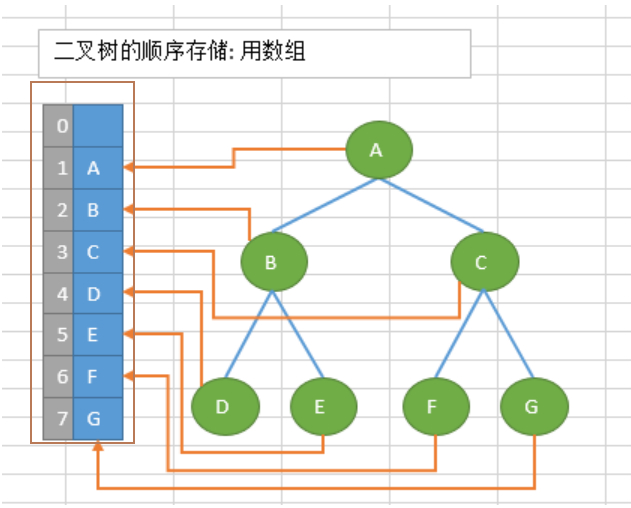
二叉树的顺序存储,指的是使用顺序表(数组)存储二叉树。需要注意的是,顺序存储只适用于完全二叉树。换句话说,只有完全二叉树才可以使用顺序表存储。因此,如果我们想顺序存储普通二叉树,需要提前将普通二叉树转化为完全二叉树。
普通二叉树转完全二叉树的方法很简单,只需给二叉树额外添加一些节点,将其"拼凑"成完全二叉树即可。如下图所示
# b. 链式存储
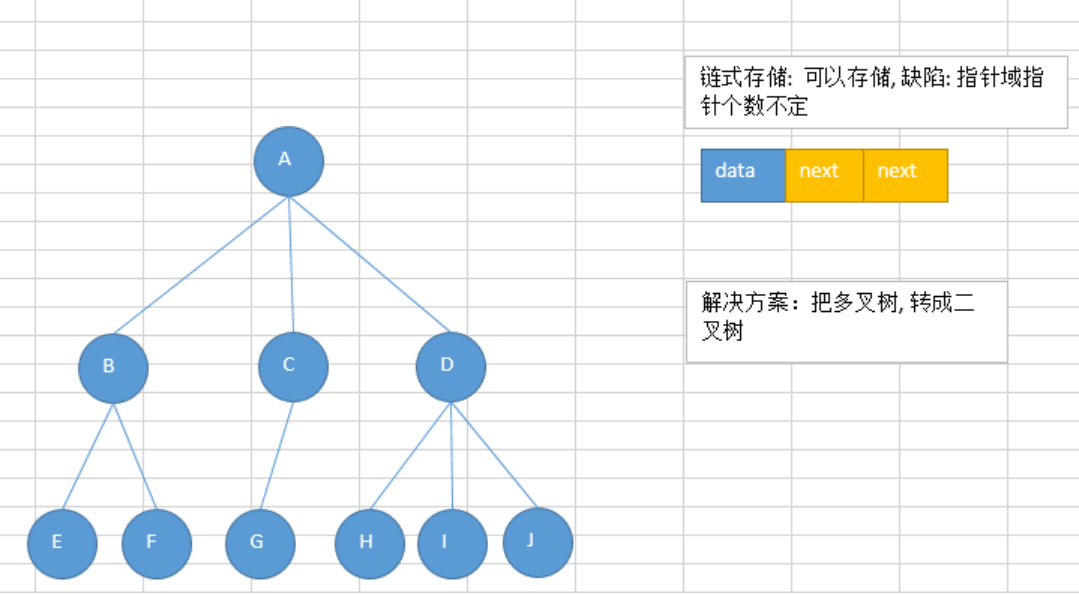
其实二叉树并不合适用数组存储,因为并不是每个二叉树都是完全二叉树,普通二叉树使用顺序表存储会存在空间浪费的现象。
# 模拟文件系统: 链式存储
"""
模拟文件系统: 链式存储
支持ls cd mkdir命令
"""
class Node(object):
def __init__(self, name, file_type='dir'):
self.name = name # 文件名称
if file_type not in ['dir', 'file']:
raise ValueError('只支持文件file或文件夹dir')
self.type = file_type # dir: 表示文件夹 file: 表示文件
self.children = [] # 文件夹下的文件
self.parent = None # 文件的上一级
def __repr__(self):
return self.name
class FileSystemTree(object):
"""模仿文件系统"""
def __init__(self):
self.root = Node('/') # 添加一个根目录 /
self.now = self.root # 当前目录
def mkdir(self, name, file_type):
"""创建文件夹/文件 文件的话没有下一级children"""
if not str(name).endswith('/'):
name = name + '/'
node = Node(name, file_type)
if file_type == 'dir':
self.now.children.append(node)
node.parent = self.now
else:
# 文件的下面不能在继续创建文件
node.parent = self.now
def ls(self):
"""查看当前目录下的所有文件名"""
return self.now.children
def cd(self, name):
"""cd命令 切换目录
cd ../ 进入上一级
cd bin/ 进入指定目录
"""
if not str(name).endswith('/'):
name = name + '/'
if name == '../': # 返回上一级
self.now = self.now.parent
return
for child in self.now.children: # 当前文件夹下找对应的文件信息
if str(child) == str(name):
self.now = child
return
raise ValueError('没有对应路径')
tree = FileSystemTree()
tree.mkdir('bin/', 'dir')
tree.mkdir('opt/', 'dir')
tree.mkdir('data/', 'dir')
tree.cd('bin/')
tree.mkdir('bin12345', 'dir')
tree.cd('../')
print(tree.ls())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
# 2.2 二叉树
# 1. 基本概念
二叉树:度不超过2的数
每个节点最多有两个孩子节点
两个孩子节点被区分位左孩子节点和右孩子节点

# 2. 二叉数类型
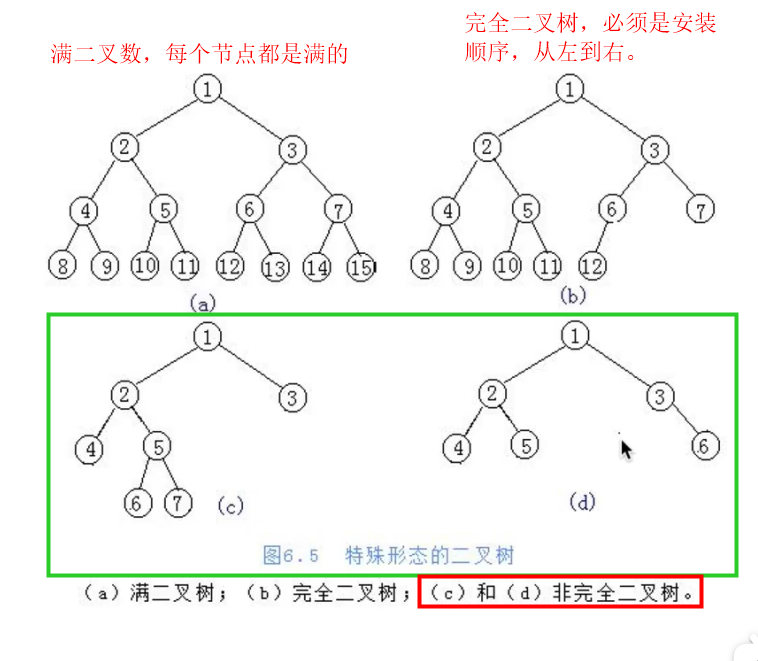
- 满二叉数:一个二叉树,如果每一层的节点都达到最大值,则这个二叉树就是满二叉树
- 完全二叉树:叶子节点只能出现在最下层和次下层,并且最下面一层的节点都集中在该层最左边的若干位置的二叉数
- 非完全二叉数
# 3. 二叉数的存储方法(表示方式)
- 链式存储方式
- 顺序存储方式
# a. 链式存储方式(链表)
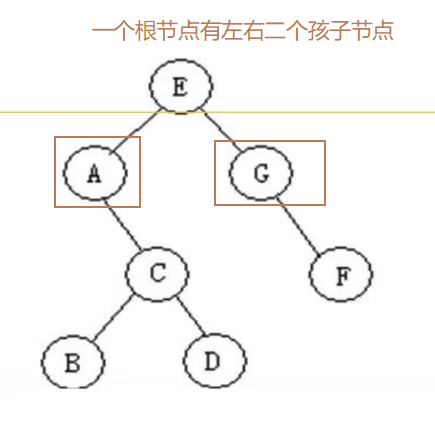
二叉树的链式存储:将二叉树的节点定义为一个对象,节点之间通过类似链表的连接方式来连接。一个根节点有左右二个孩子节点
"""
用链式存储表示二叉树
"""
class BiTreeNode(object):
def __init__(self, node):
self.node = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
def __repr__(self):
return self.node
A = BiTreeNode('A')
B = BiTreeNode('B')
C = BiTreeNode('C')
D = BiTreeNode('D')
E = BiTreeNode('E')
F = BiTreeNode('F')
G = BiTreeNode('G')
# E
E.left_child = A
E.right_child = G
# A
A.right_child = C
# C
C.left_child = B
C.right_child = D
# G
G.right_child = F
print(E.left_child.right_child.right_child) # D
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# b. 顺序存储方式(列表)
父节点和左孩子节点的编号下标有什么关系?
0-1 1-3 2-5 3-7 4-9
# 规律:i --> 2i+1(左孩子)
父节点和右孩子节点的编号下标有什么关系?
- 0-2 1-4 2-6 3-8 4-10
- 规律:i --> 2i+2(右孩子)
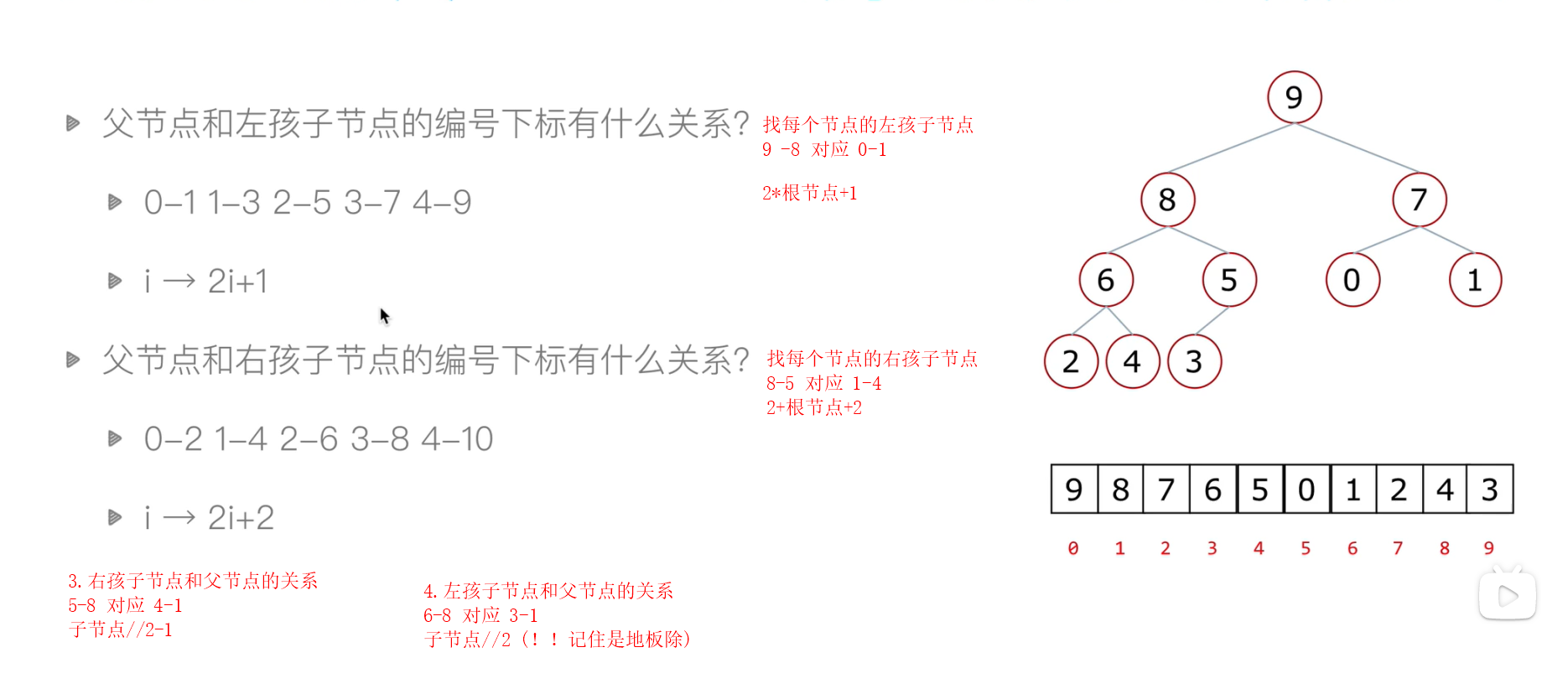
通过父节点(i)找左孩子节点 i --> 2i+1 通过父节点找右孩子节点 i --> 2i+2
通过子节点(i)找父节点 i -- > (i-1)/2
1.父结点索引:(i-1)/2(这里计算机中的除以2,省略掉小数)
2.左孩子索引:2*i+1
3.右孩子索引:2*i+2
所以上面两个数组可以脑补成堆结构,因为他们满足堆的定义性质: # arr表示列表
大根堆:arr(i)>arr(2*i+1) && arr(i)>arr(2*i+2)
小根堆:arr(i)<arr(2*i+1) && arr(i)<arr(2*i+2)
2
3
4
5
6
7
# 4. 二叉树的遍历
二叉树的遍历方式:
- 前序遍历:先处理根,之后是左子树,然后是右子树
- 中序遍历:先处理左子树,之后是根,最后是右子树(输出的顺序正好是有序的)
- 后序遍历:先处理左子树,之后是右子树,最后是根
- 层次遍历:按照一层一层的顺序从左往右把节点放到一个队列里
前三种是以递归的形式,层次遍历是以队列的形式
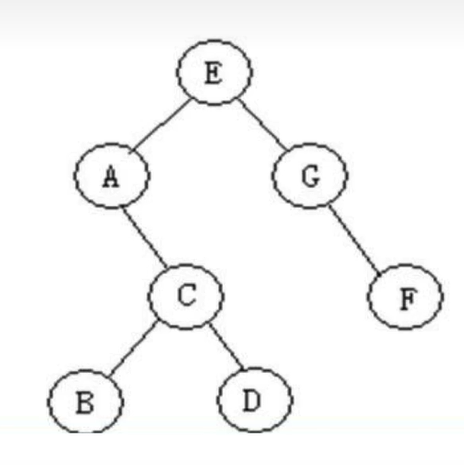
"""
二叉树的遍历:
- 前序遍历:**先处理根,之后是左子树,然后是右子树**
- 中序遍历:**先处理左子树,之后是根,最后是右子树**
- 后序遍历:**先处理左子树,之后是右子树,最后是根**
- 层次遍历:**按照一层一层的顺序从左往右把节点放到一个队列里**
"""
class BiTreeNode(object):
def __init__(self, node):
self.node = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
def __repr__(self):
return self.node
A = BiTreeNode('A')
B = BiTreeNode('B')
C = BiTreeNode('C')
D = BiTreeNode('D')
E = BiTreeNode('E')
F = BiTreeNode('F')
G = BiTreeNode('G')
# E
E.left_child = A
E.right_child = G
# A
A.right_child = C
# C
C.left_child = B
C.right_child = D
# G
G.right_child = F
root = E
def forward_order(root):
"""前序遍历: 处理根,之后是左子树,然后是右子树"""
if root:
print(root.node, end=' ') # 处理根
forward_order(root.left_child) # 处理左子树
forward_order(root.right_child) # 处理右子树
forward_order(root) # E A C B D G F
print('\n')
def mid_order(root):
"""中序遍历: 先处理左子树,之后是根,最后是右子树"""
if root:
mid_order(root.left_child) # 处理左子树
print(root.node, end=' ') # 处理根
mid_order(root.right_child) # 处理右子树
mid_order(root) # A B C D E G F
print('\n')
def back_order(root):
"""后序遍历:先处理左子树,之后是右子树,最后是根"""
if root:
back_order(root.left_child) # 处理左子树
back_order(root.right_child) # 处理右子树
print(root.node, end=' ') # 处理根
back_order(root) # B D C A F G E
print('\n')
from collections import deque
def level_order(root):
"""层次遍历:**按照一层一层的顺序从左往右把节点放到一个队列里"""
queue = deque()
queue.append(root) # 链表
while len(queue) > 0:
node = queue.popleft() # 队列种取元素
print(node.node, end=' ')
if node.left_child:
queue.append(node.left_child)
if node.right_child:
queue.append(node.right_child)
level_order(root) # E A G C F B D
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
# 5. 二叉搜索树
https://python-data-structures-and-algorithms.readthedocs.io/zh/latest/17_%E4%BA%8C%E5%8F%89%E6%9F%A5%E6%89%BE%E6%A0%91/binary_search_tree/
二叉搜索树是一颗二叉树且满足性质:设X是二叉树的一个节点。如果Y是X左子树的一个节点,那么Y.key <= X.key;如果Y是X右子树的一个节点,那么Y.key >= X.key
二叉查找树是这样一种二叉树结构,它的每个节点包含一个 key 和它附带的数据,对于每个内部节点 V:
- 所有 key 小于 V 的都被存储在 V 的左子树
- 所有 key 大于 V 的都存储在 V 的右子树
说白了就是对于每个内部节点,左子树的 key 都比它小,右子树都比它大。
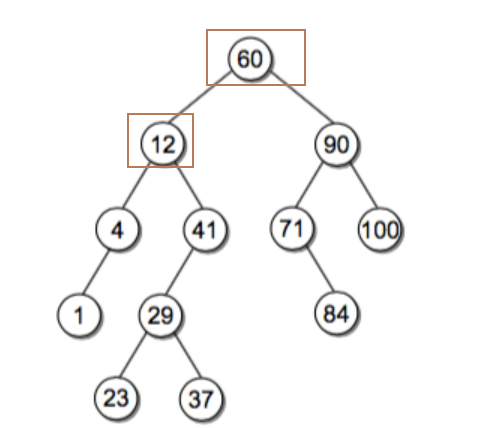
如果中序遍历(二叉树遍历讲过了)这颗二叉树,你会发现输出的顺序正好是有序的
# a. 插入
插入节点的时候我们需要一直保持 BST 的性质,每个内部节点,左子树的 key 都比它小,右子树都比它大
"""
插入节点的时候我们需要一直保持 BST 的性质,每个内部节点,左子树的 key 都比它小,右子树都比它大
"""
class BiTreeNode(object):
"""链式存储节点"""
def __init__(self, node):
self.data = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
self.parent = None
# def __repr__(self):
# return self.data
class BST(object):
def __init__(self, li=None):
self.root = None
if li:
for element in li:
# self.root = self.insert(self.root, element) # 递归方法
self.insert_no_res(element)
def insert(self, current_node, value):
"""使用递归的方式插入节点"""
if not current_node: # 1、根节点没有元素,直接插入
current_node = BiTreeNode(value)
elif current_node.data > value: # 2、根节点大于value,插入到左子树
current_node.left_child = self.insert(current_node.left_child, value)
current_node.left_child.parent = current_node
elif current_node.data < value: # 3、根节点小于value,插入到右子树
current_node.right_child = self.insert(current_node.right_child, value)
current_node.right_child.parent = current_node
# 4、有等于的清空,这里忽略了,后面可以自定义规则,插入左边还是右边
return current_node
def insert_no_res(self, value):
"""不使用递归的方式"""
p = self.root
if not p: # 1、当节点为空的时候直接插入
self.root = BiTreeNode(value)
return
while True:
if p.data > value: # 2、根节点大,存放到左边
if p.left_child: # 如果存放的左节点存在,则向下进入一层
p = p.left_child
else:
p.left_child = BiTreeNode(value)
p.left_child.parent = p
return
elif p.data < value: # 3、根节点小,存放到右边
if p.right_child: # 如果存放的右节点存在,则向下进入一层
p = p.right_child
else:
p.right_child = BiTreeNode(value)
p.right_child.parent = p
return
else:
return
# 4、如果有相等的元素,这里忽略了,后面可以自定义规则,插入左边还是右边
def forward_order(self, root):
"""前序遍历: 处理根,之后是左子树,然后是右子树"""
if root:
print(root.data, end=' ') # 处理根
self.forward_order(root.left_child) # 处理左子树
self.forward_order(root.right_child) # 处理右子树
def mid_order(self, root):
"""中序遍历: 先处理左子树,之后是根,最后是右子树"""
if root:
self.mid_order(root.left_child) # 处理左子树
print(root.data, end=' ') # 处理根
self.mid_order(root.right_child) # 处理右子树
def back_order(self, root):
"""后序遍历:先处理左子树,之后是右子树,最后是根"""
if root:
self.back_order(root.left_child) # 处理左子树
self.back_order(root.right_child) # 处理右子树
print(root.data, end=' ') # 处理根
bst = BST([1, 4, 2, 6, 3, 9, 8, 7, 0])
print(bst)
bst.forward_order(bst.root)
print('')
bst.mid_order(bst.root)
print('')
bst.back_order(bst.root)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
# b. 查找
如何查找一个指定的节点呢,根据定义我们知道每个内部节点左子树节点的 key 都比它小,右子树节点的 key 都比它大,所以 对于带查找的节点 search_key,从根节点开始,如果 search_key 大于当前 key,就去右子树查找,否则去左子树查找。 一直到当前节点是 None 了说明没找到对应 key。
获取最大和最小 key 的节点
其实还按照其定义,最小值就一直向着左子树找,最大值一直向右子树找,递归查找就行。
- 使用递归方式查找
- 使用循环方式查找
- 获取最大和最小 key 的节点
"""
每个内部节点左子树节点的 key 都比它小,右子树节点的key都比它大,所以对于带查找的节点 search_key从根节点开始:
1、如果 search_key 大于当前节点key,就去右子树查找,
2、如果 search_key 小于当前节点key,就去左子树查找,
3、直到当前节点是 None 了说明没找到对应 key。
"""
class BiTreeNode(object):
"""链式存储节点"""
def __init__(self, node):
self.data = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
self.parent = None
class BST(object):
def __init__(self, li=None):
self.root = None
if li:
for element in li:
self.root = self.insert(self.root, element) # 递归方法
# self.insert_no_rec(element)
def insert(self, current_node, value):
"""使用递归的方式插入节点"""
if not current_node: # 1、根节点没有元素,直接插入
current_node = BiTreeNode(value)
elif current_node.data > value: # 2、根节点大于value,插入到左子树
current_node.left_child = self.insert(current_node.left_child, value)
current_node.left_child.parent = current_node
elif current_node.data < value: # 3、根节点小于value,插入到右子树
current_node.right_child = self.insert(current_node.right_child, value)
current_node.right_child.parent = current_node
# 4、有等于的清空,这里忽略了,后面可以自定义规则,插入左边还是右边
return current_node
def insert_no_rec(self, value):
"""不使用递归的方式"""
p = self.root
if not p: # 1、当节点为空的时候直接插入
self.root = BiTreeNode(value)
return
while True:
if p.data > value: # 2、根节点大,存放到左边
if p.left_child: # 如果存放的左节点存在,则向下进入一层
p = p.left_child
else:
p.left_child = BiTreeNode(value)
p.left_child.parent = p
return
elif p.data < value: # 3、根节点小,存放到右边
if p.right_child: # 如果存放的右节点存在,则向下进入一层
p = p.right_child
else:
p.right_child = BiTreeNode(value)
p.right_child.parent = p
return
else:
return
# 4、如果有相等的元素,这里忽略了,后面可以自定义规则,插入左边还是右边
def query(self, current_node, value):
"""查找二叉树是否有此元素:递归"""
if not current_node: # 1、当前节点为None表示没有元素
return None
if current_node.data < value: # 2、value大于当前节点去右子树找
return self.query(current_node.right_child, value)
elif current_node.data > value: # 3、value小于当前节点去左子树找
return self.query(current_node.left_child, value)
else:
return current_node.data # 否则找到元素
def query_no_rec(self, value):
"""查找二叉树是否有此元素:循环"""
p = self.root
while p:
if p.data < value: # 1、value大于当前节点去右子树找
p = p.right_child
elif p.data > value: # 2、value小于当前节点去左子树找
p = p.left_child
else:
return p
return None # 没有找到
def min_node(self, current_node):
"""获取最小的节点:最小值就一直向着左子树找"""
if not current_node:
return None
if current_node.left_child is None: # 左子树最小值
return current_node
else:
return self.min_node(current_node.left_child)
def max_node(self, current_node):
"""获取最大的节点:最大值一直向右子树找"""
if not current_node:
return None
if current_node.right_child is None: # 左子树最小值
return current_node
else:
return self.max_node(current_node.right_child)
def forward_order(self, root):
"""前序遍历: 处理根,之后是左子树,然后是右子树"""
if root:
print(root.data, end=' ') # 处理根
self.forward_order(root.left_child) # 处理左子树
self.forward_order(root.right_child) # 处理右子树
def mid_order(self, root):
"""中序遍历: 先处理左子树,之后是根,最后是右子树"""
if root:
self.mid_order(root.left_child) # 处理左子树
print(root.data, end=' ') # 处理根
self.mid_order(root.right_child) # 处理右子树
def back_order(self, root):
"""后序遍历:先处理左子树,之后是右子树,最后是根"""
if root:
self.back_order(root.left_child) # 处理左子树
self.back_order(root.right_child) # 处理右子树
print(root.data, end=' ') # 处理根
bst = BST([1, 4, 2, 6, 3, 9, 8, 7, 0])
# bst.mid_order(bst.root)
print(bst.query(bst.root, 2))
print(bst.query_no_rec(2).data)
print('最小节点: ', bst.min_node(bst.root).data)
print('最大节点: ', bst.max_node(bst.root).data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
# c. 删除
删除操作相比上边的操作要麻烦很多,首先需要定位一个节点,删除节点后,我们需要始终保持 BST 的性质。 删除一个节点涉及到三种情况:
- 节点是叶子节点
- 节点有一个孩子
- 节点有两个孩子
我们分别来看看三种情况下如何删除一个节点:
删除叶子节点
这是最简单的一种情况,只需要把它的父亲指向它的指针设置为 None 就好。比如删除23
def remove_leaf_node(self, node):
"""删除叶子节点: 把它的父亲节点指向它的指针设置为 None"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = None
if node == node.parent.left_child: # 2、删除的是node的左孩子节点
node.parent.left_child = None
else:
node.parent.right_child = None # 3、删除的是node的右孩子节点
2
3
4
5
6
7
8
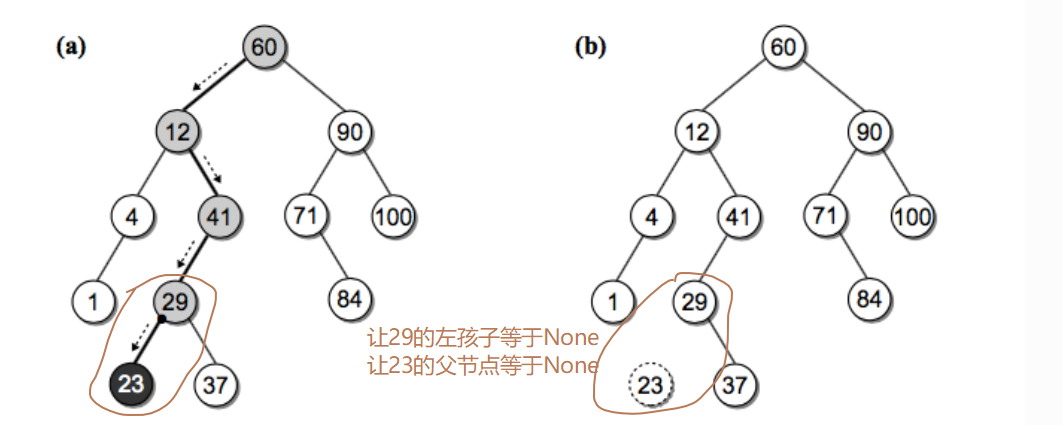
删除只有一个孩子的节点
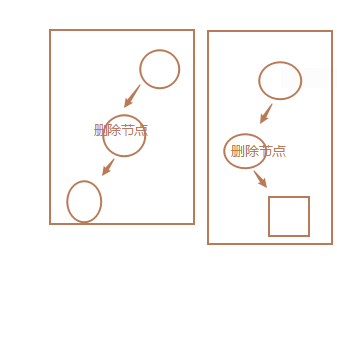
删除有一个孩子的节点时,我们拿掉需要删除的节点,之后把它的父亲指向它的孩子就行,因为根据 BST 左子树都小于节点,右子树都大于节点的特性,删除它之后这个条件依旧满足。有二种方式:1、node仅有一个左孩子节点 2、node仅有一个右孩子节点
方式一:node仅有一个左孩子节点
def remove_one_left_child_node(self, node):
"""删除node节点,node仅有一个左孩子节点(仅有一个孩子节点): 拿掉需要删除的节点,之后把它的父亲指向它的孩子"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = node.left_chlid
return
if node == node.parent.left_child: # 2、删除节点node是父节点的左孩子节点
node.parent.left_child = node.left_child # 根据node节点重新添加node的父节点和node的子节点
node.left_child.parent = node.parent
else: # 3、删除节点node是父节点的右孩子节点
node.parent.right_child = node.left_child
node.left_child.parent = node.parent
2
3
4
5
6
7
8
9
10
11
方式二:node仅有一个右孩子节点
def remove_one_right_child_node(self, node):
"""删除node节点,node仅有一个右孩子节点(仅有一个孩子节点): 拿掉需要删除的节点,之后把它的父亲指向它的孩子"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = node.right_child
return
if node == node.parent.left_child: # 2、删除节点node是父节点的左孩子节点
node.parent.left_child = node.right_child # 根据node节点重新添加node的父节点和node的子节点
node.right_child.parent = node.parent
else: # 3、删除节点node是父节点的右孩子节点
node.parent.right_child = node.right_child
node.right_child.parent = node.parent
2
3
4
5
6
7
8
9
10
11
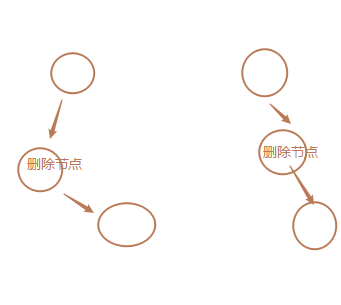
删除节点有两个孩子节点
如果要删除的节点右两个孩子节点:将其右子树的最小节点(该节点最多有一个右孩子)删除,并替换当前节点。!1、注意先找到右子树最小节点 / 2、删除node节点的值替换(node.data = min_node.data)/ 3、删除右子树最小节点,考虑右子树的最小节点是否还满足上面的情况
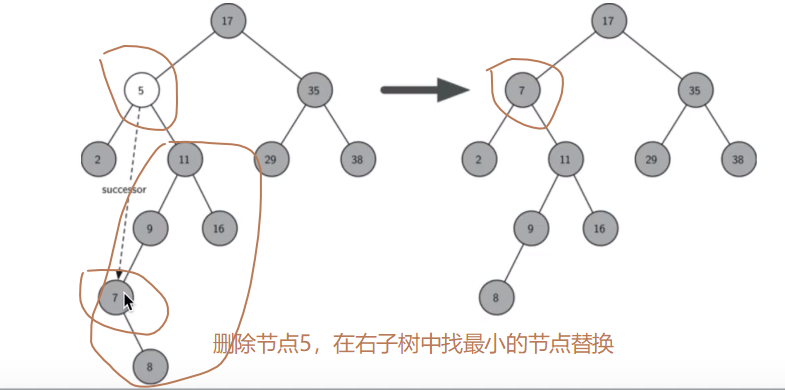
删除示例
"""
删除二叉搜索树节点
- 节点是叶子节点
把它的父亲节点指向它的指针设置为 None
- 节点有一个孩子
拿掉需要删除的节点,之后把它的父亲指向它的孩子就行
- 删除的是node节点左孩子
node节点在是父节点的左孩子
node.parent.left_child = node.left_child # 根据node节点重新添加node的父节点和node的子节点
node.left_child.parent = node.parent
node节点在是父节点的右孩子
node.parent.right_child = node.left_child
node.left_child.parent = node.parent
- 删除的是node节点右孩子
node节点在是父节点的左孩子
node.parent.left_child = node.right_child # 根据node节点重新添加node的父节点和node的子节点
node.right_child.parent = node.parent
node节点在是父节点的右孩子
node.parent.right_child = node.right_child
node.right_child.parent = node.parent
- 节点有两个孩子
将其右子树的最小节点(该节点最多有一个右孩子)删除,并替换当前节点
- 将找到的右子树最小节点和删除节点的值替换
node.data=current_node.data
- 判断右子树最小节点是否是:
右子树、
根节点、
"""
class BiTreeNode(object):
"""链式存储节点"""
def __init__(self, node):
self.data = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
self.parent = None
class BST(object):
def __init__(self, li=None):
self.root = None
if li:
for element in li:
# self.root = self.insert(self.root, element) # 递归方法
self.insert_no_rec(element)
def insert(self, current_node, value):
"""使用递归的方式插入节点"""
if not current_node: # 1、根节点没有元素,直接插入
current_node = BiTreeNode(value)
elif current_node.data > value: # 2、根节点大于value,插入到左子树
current_node.left_child = self.insert(current_node.left_child, value)
current_node.left_child.parent = current_node
elif current_node.data < value: # 3、根节点小于value,插入到右子树
current_node.right_child = self.insert(current_node.right_child, value)
current_node.right_child.parent = current_node
# 4、有等于的清空,这里忽略了,后面可以自定义规则,插入左边还是右边
return current_node
def insert_no_rec(self, value):
"""不使用递归的方式"""
p = self.root
if not p: # 1、当节点为空的时候直接插入
self.root = BiTreeNode(value)
return
while True:
if p.data > value: # 2、根节点大,存放到左边
if p.left_child: # 如果存放的左节点存在,则向下进入一层
p = p.left_child
else:
p.left_child = BiTreeNode(value)
p.left_child.parent = p
return
elif p.data < value: # 3、根节点小,存放到右边
if p.right_child: # 如果存放的右节点存在,则向下进入一层
p = p.right_child
else:
p.right_child = BiTreeNode(value)
p.right_child.parent = p
return
else:
return
# 4、如果有相等的元素,这里忽略了,后面可以自定义规则,插入左边还是右边
def query(self, current_node, value):
"""查找二叉树是否有此元素:递归"""
if not current_node: # 1、当前节点为None表示没有元素
return None
if current_node.data < value: # 2、value大于当前节点去右子树找
return self.query(current_node.right_child, value)
elif current_node.data > value: # 3、value小于当前节点去左子树找
return self.query(current_node.left_child, value)
else:
return current_node.data # 否则找到元素
def query_no_rec(self, value):
"""查找二叉树是否有此元素:循环"""
p = self.root
while p:
if p.data < value: # 1、value大于当前节点去右子树找
p = p.right_child
elif p.data > value: # 2、value小于当前节点去左子树找
p = p.left_child
else:
return p
return None # 没有找到
def min_node(self, current_node):
"""获取最小的节点:最小值就一直向着左子树找"""
if not current_node:
return None
if current_node.left_child is None: # 左子树最小值
return current_node
else:
return self.min_node(current_node.left_child)
def max_node(self, current_node):
"""获取最大的节点:最大值一直向右子树找"""
if not current_node:
return None
if current_node.right_child is None: # 左子树最小值
return current_node
else:
return self.max_node(current_node.right_child)
def forward_order(self, root):
"""前序遍历: 处理根,之后是左子树,然后是右子树"""
if root:
print(root.data, end=' ') # 处理根
self.forward_order(root.left_child) # 处理左子树
self.forward_order(root.right_child) # 处理右子树
def mid_order(self, root):
"""中序遍历: 先处理左子树,之后是根,最后是右子树"""
if root:
self.mid_order(root.left_child) # 处理左子树
print(root.data, end=' ') # 处理根
self.mid_order(root.right_child) # 处理右子树
def back_order(self, root):
"""后序遍历:先处理左子树,之后是右子树,最后是根"""
if root:
self.back_order(root.left_child) # 处理左子树
self.back_order(root.right_child) # 处理右子树
print(root.data, end=' ') # 处理根
def remove_leaf_node(self, node):
"""删除叶子节点: 把它的父亲节点指向它的指针设置为 None"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = None
if node == node.parent.left_child: # 2、删除的是node的左孩子节点
node.parent.left_child = None
else:
node.parent.right_child = None # 3、删除的是node的右孩子节点
def remove_one_left_child_node(self, node):
"""删除node节点,node仅有一个左孩子节点(仅有一个孩子节点): 拿掉需要删除的节点,之后把它的父亲指向它的孩子"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = node.left_chlid
return
if node == node.parent.left_child: # 2、删除节点node是父节点的左孩子节点
node.parent.left_child = node.left_child # 根据node节点重新添加node的父节点和node的子节点
node.left_child.parent = node.parent
else: # 3、删除节点node是父节点的右孩子节点
node.parent.right_child = node.left_child
node.left_child.parent = node.parent
def remove_one_right_child_node(self, node):
"""删除node节点,node仅有一个右孩子节点(仅有一个孩子节点): 拿掉需要删除的节点,之后把它的父亲指向它的孩子"""
if not node.parent: # 1、没有parent父节点,表示的就是根节点
self.root = node.right_child
return
if node == node.parent.left_child: # 2、删除节点node是父节点的左孩子节点
node.parent.left_child = node.right_child # 根据node节点重新添加node的父节点和node的子节点
node.right_child.parent = node.parent
else: # 3、删除节点node是父节点的右孩子节点
node.parent.right_child = node.right_child
node.right_child.parent = node.parent
def delete_node(self, element):
"""删除节点:三种情况"""
if self.root:
node = self.query_no_rec(element) # 1、查找二叉树是否有此元素
if not node:
raise ValueError('二叉树没有此元素')
if not node.left_child and not node.right_child: # 2、如果删除的节点没有左右子树,表示就是删除叶子节点(第一种情况)
self.remove_leaf_node(node)
elif not node.left_child: # 3、删除节点没有左子树(第二种情况,删除节点只有右孩子节点)
self.remove_one_right_child_node(node)
elif not node.right_child: # 4、删除节点没有右子树(第二种情况,删除节点只有左孩子节点)
self.remove_one_left_child_node(node)
else:
# 5、删除节点有左右孩子节点
# 5.1 找到右子树最小的节点,和删除node节点的值替换
min_node = self.min_node(node)
print(min_node.data, 333)
node.data = min_node.data
# 5.2 删除右子树最小节点,考虑右子树的最小节点是否还满足上面的情况
if min_node.right_child:
self.remove_one_right_child_node(min_node)
else:
self.remove_leaf_node(min_node)
bst = BST([1, 3, 5, 7, 2, 4, 6])
bst.mid_order(bst.root)
print('')
bst.delete_node(3)
bst.mid_order(bst.root)
print('')
bst.delete_node(7)
bst.mid_order(bst.root)
print('')
bst.delete_node(1)
bst.mid_order(bst.root)
print('')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
# 6. 二叉搜索树的效率
- 平均情况下,二叉搜索树进行搜索的时间复杂度为O(logn)
- 最坏情况下,二叉树搜索树可能非常倾斜。
- 解决方法
- 随机插入
- AVL树
- 解决方法
# 2.3 AVL树
csdn: https://www.cnblogs.com/leipDao/p/10097001.html
favtutor: https://favtutor.com/blogs/avl-tree-python
https://www.askpython.com/python/examples/avl-tree-in-python
csdn
https://blog.csdn.net/qq_41784749/article/details/113761106?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166028648016781647523487%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=166028648016781647523487&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~top_positive~default-1-113761106-null-null.142^v40^pc_rank_34_2,185^v2^control&utm_term=AVL%E6%A0%91&spm=1018.2226.3001.4187
2
3
4
5
当二叉树倾斜时,运行时间复杂度变成最坏的情况,即 O(n),但在 AVL 树的情况下,时间复杂度仍然为 O(logn)。因此,始终建议使用 AVL 树而不是二叉搜索树。
请记住,每个 AVL 树都是二叉搜索树,但每个二叉搜索树都不一定是 AVL 树。
- AVL树:AVL树是一颗自平衡的二叉搜索树
- AVL树具有一下性质:
- 根的左右子树的高度之差的绝对值不能超过1
- 根的左右子树都是平衡二叉树
# 1. 平衡因子
平衡因子就是二叉排序树中每个结点的左子树和右子树的高度差。平衡因子=左子树高度 - 右子树高度
这里需要注意有的博客或者书籍会将平衡因子定义为右子树与左子树的高度差,本篇我们定义为左子树与右子树的高度差,不要搞混。
比如下图中: 根结点45的平衡因子为-1 (左子树高度2,右子树高度3) 2-3 50结点的平衡因子为-2 (左子树高度0,右子树高度2) 0-2 40结点的平衡因子为0 (左子树高度1,右子树高度1) 1-1
根据定义这颗二叉排序树中有结点的平衡因子超过1,所以不是一颗AVL树。
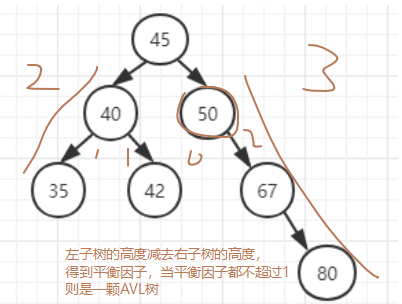
所以AVL树可以表述如下:一棵AVL树是其每个结点的左右子树高度差绝对值最多相差1的二叉查找树。
# 2. 最小不平衡二叉排序树
最小不平衡二叉树定义为:距离插入结点最近,且平衡因子绝对值大于2的结点为根结点的子树,称为最小不平衡二叉排序树。
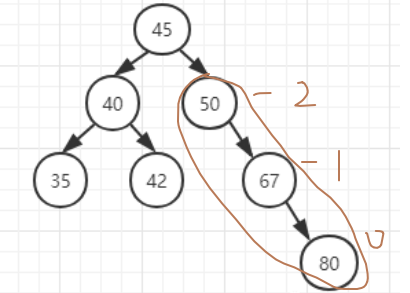
在插入80结点之前是一颗标准的AVL树,在插入80结点之后就不是了,我们查找一下最小不平衡二叉排序树,从距离80结点最近的结点开始,67结点平衡因子为-1,50结点平衡因子为-2,到这里就找到了,所以以50为根结点的子树就是最小不平衡二叉排序树。
# 3. AVL树-插入(旋转)
当对 AVL 树进行插入和删除等操作时,可能会影响树的平衡因子。如果在插入或删除元素之后,任何节点的平衡因子都会受到影响,那么这个问题可以通过使用旋转来解决。因此,使用旋转来恢复搜索树的平衡。旋转是将树的节点向左或向右移动以使树高度平衡树的方法。
插入一个节点可能会破坏AVL树的平衡,比如上面插入80的情况,可以通过旋转操作来进行修正。
插入一个节点后,只有从插入节点到根节点的路径上的节点平衡可能被改变。我们需要找出第一个破坏了平衡条件的节点,称之为k,k的两颗子树的高度差2. 比如从距离80结点最近的结点开始,67结点平衡因子为-1,50结点平衡因子为-2,到这里就找到了,所以以50为根结点的子树就是最小不平衡二叉排序树。
不平衡的出现可能有4种情况:
- 左旋
- 右旋
- 左旋-右旋
- 右旋-左旋
左旋与右旋就是为了解决不平衡问题而产生的,我们构建一颗AVL树的过程会出现结点平衡因子绝对值大于1的情况,这时就可以通过左旋或者右旋操作来达到平衡的目的。
# a. 左旋(RR)
不平衡是由于对X的右孩子的右子树插入导致的:左旋
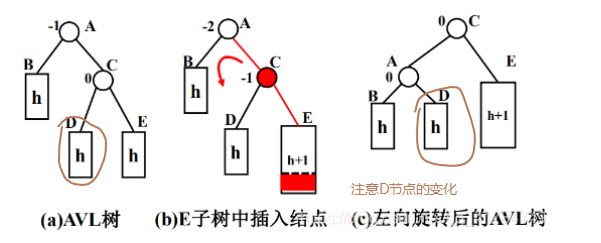
在第一步图示仅仅将X结点进行左旋,成为Y结点的一个子节点。
但是此时出现一个问题,就是Y结点有了三个子节点,这连最基础的二叉树都不是了,所以需要进行第二部操作。
在第二部操作的时候,我们将B结点设置为X结点的右孩子,这里可以仔细想一下,B结点一开始为X结点的右子树Y的左孩子,那么其肯定比X结点大,比Y结点小,所以这里设置为X结点的右孩子是没有问题的。
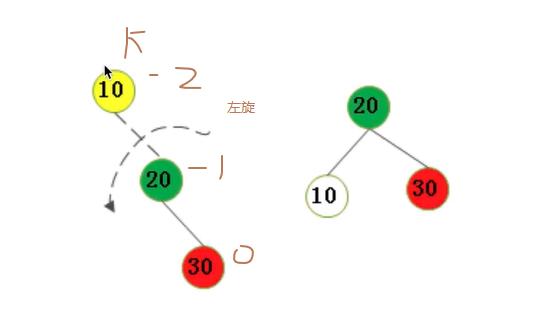
上图中20结点没有左子树,只有右子树,那么第二部也就不需要操作了
到这里一个标准的左旋流程就完成了。
# b. 右旋(LL)
不平衡是由于对K的左孩子的左子树插入导致的:右旋
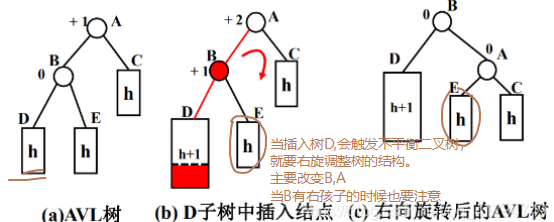
第一步同样仅仅将Y结点右旋,成为X的一个结点,同样这里会出现问题X有了三个结点。
第二步,如果一开始Y左子树存在右结点,上图中也就是B结点,则将其设置为Y的右孩子。
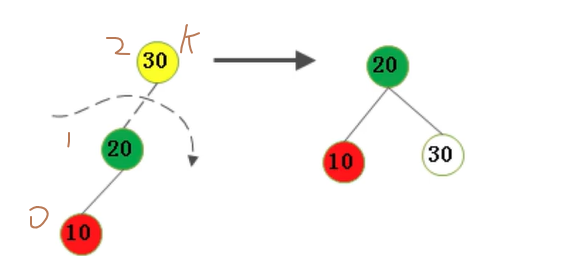
上图中20结点没有右子树,只有左子树,那么第二部也就不需要操作了
# c. 右旋-左旋(RL)
不平衡是由于对B的右孩子的左子树插入导致的:右旋-左旋
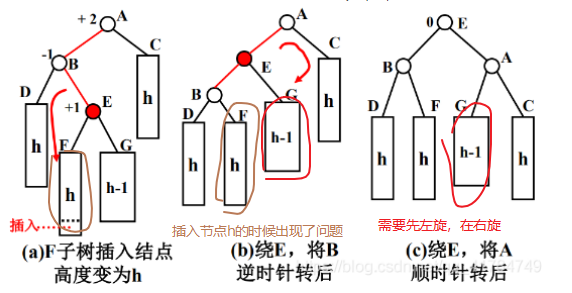
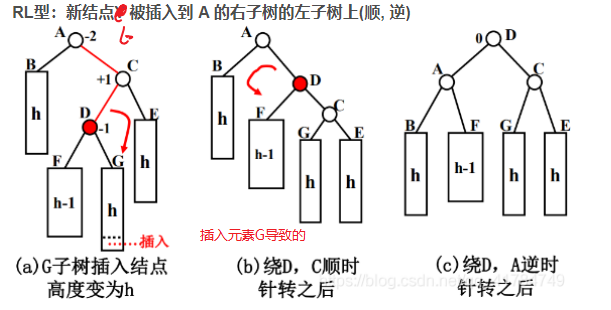
# d. 左旋-右旋(LR)
不平衡是由于对C的左孩子的右子树插入导致的:左旋-右旋
# 还有一些问题
https://www.cnblogs.com/steven2020/p/10687170.html
"""
每个AVL树都是二叉搜索树
最小不平衡二叉排序树
balance_factor平衡因子 = 左子树高度 - 右子树高度(给每个节点的平衡因子添加上)
4种旋转方式:
- 左旋 节点的右孩子的右子树插入导致的(x --> y --> z)
y 有左孩子的情况
y 没有左孩子的情况
"""
class BiTreeNode(object):
"""链式存储节点"""
def __init__(self, node):
self.data = node
self.left_child = None # 左孩子
self.right_child = None # 右孩子
self.parent = None
self.bf = 0 # 节点的平衡因子
class AVLTree(object):
"""AVL树"""
def __init__(self, li=None):
self.root = None
if li:
for element in li:
self.insert_to_rec(element) # 递归方法
def LL(self, A, C): # 传参是插入节点的(父节点的父节点,父节点)
"""左旋转: 对A的右孩子的右子树插入导致的(插入节点E)
情况一:
A C
B C A E
D E B D
情况二:
A B
B A C
C
1、找到需要变化的节点 D, 如果D存在则插入链表中
2、重写指向旋转后的链表,C,A
3、更新平衡因子bf
"""
D = C.left_child
A.right_child = D
if D: # 判断B是否有右孩子节点(情况一),情况二的话就不要这些步骤
D.parent = A
C.left_child = A
A.parent = C
A.bf = 0
C.bf = 0
return C # 返回根节点
def RR(self, A, B): # 传参是插入节点的(父节点的父节点,父节点)
"""右旋转: 对A的左孩子的左子树插入导致的(插入节点D)
情况一:
A B
B C D A
D E E C
情况二:
A B
B C A
C
1、找到需要变化的节点 E, 如果E存在则插入链表中
2、重写指向旋转后的链表,B,A
3、更新平衡因子bf
"""
E = A.left_child
A.left_child = E
if E: # 判断B是否有右孩子节点(情况一),情况二的话就不要这些步骤
E.parent = A
B.right_child = A #
A.parent = B
A.bf = 0
B.bf = 0
return B # 返回根节点
def LR(self, A, B): # 传参是插入节点的(父节点的父节点,父节点)
"""左旋-右旋: 对B节点的右孩子的左子树插入导致的(插入节点F)
情况一:
A A E
B C E C B A
D E B G D F G C
F G D F
1、找到插入节点的父节点E
左旋
2、得到需要变化的节点 F, 如果F存在则插入链表中
3、重写指向旋转后的链表,B,E
右旋
4、得到需要变化的节点G, 如果G存在则插入链表中
5、重写指向旋转后的链表,E,A
6、更新平衡因子
平衡因子不可能超过2或者-2
"""
# 1、先左旋,第二个图,先处理好F的位置
E = B.right_child
F = E.left_child # F
B.right_child = F
if F:
F.parent = B
E.left_child = B
B.parent = E
# 2、第二个图右旋,先处理好G的位置
G = E.right_child # G
A.left_child = G
if G:
G.parent = A
E.right_child = A
A.parent = E
# ! 平衡因子不可能超过2或者-2
# 更新平衡因子,判断E根节点(最小不平衡二叉排序树的根节点)的平衡因子,来更新子节点的平衡因子 balance_factor平衡因子 = 左子树高度 - 右子树高度(给每个节点的平衡因子添加上)
if E.bf < 0: # E的平衡因子 小于0,表示左孩子的平衡因子比右孩子的平衡因子大 B - A = -1
A.bf = 1
# A.bf = -1
B.bf = 0
elif E.bf > 0: # E的平衡因子 大于0,表示左孩子的平衡因子比右孩子的平衡因子小 B - A = 1
A.bf = 0
B.bf = -1
# B.bf = 1
else: # 左右孩子平衡因子都相等 B - A = 0
A.bf = 0
B.bf = 0
E.bf = 0
return E
def RL(self, A, C): # 传参是 最小不平衡二叉排序树的 根节点和旗下的右孩子节点
"""右旋-左旋: 对B节点的右孩子的左子树插入导致的(插入节点F)
情况一:
A A D
B C B D A C
D E F C B F G E
F G G E
1、找到插入节点的父节点D
右旋
2、得到需要变化的节点 G, 如果G存在则插入链表中
3、重写指向旋转后的链表,D,C
左旋
4、得到需要变化的节点F, 如果F存在则插入链表中
5、重写指向旋转后的链表,D,A
6、更新平衡因子
平衡因子不可能超过2或者-2
"""
# 1、先右旋,第二个图,先处理好G的位置
D = C.left_child
G = D.right_child # 拿到G的位置,直接放到C的左孩子
C.left_child = G
if G:
G.parent = C
D.right_child = C
C.parent = D
# 2、第二个图右旋,先处理好F的位置
F = D.left_child # 拿到F的位置
A.right_child = F
if F:
F.parent = A
D.left_child = A # 旋转
A.parent = D
# 更新平衡因子,通过D(最小不平衡二叉排序树的根节点)来更新子节点的平衡因子 左-右
if D.bf < 0:
A.bf = -1
# A.bf = 0
C.bf = 0
elif D.bf > 0:
A.bf = 0
# C.bf = -1
C.bf = 1
else:
A.bf = 0
C.bf = 0
D.bf = 0
return D
def insert_to_rec(self, element):
"""插入
一、插入节点到树中
node: 存储插入的节点
二、调整balance_factor平衡因子
三、连接旋转后的子树
"""
# 一、插入节点到树中
p = self.root
if not p:
self.root = BiTreeNode(element)
return
while True:
if p.data > element: # 插入值小于节点,插入左子树
if p.left_child:
p = p.left_child
else:
p.left_child = BiTreeNode(element)
p.left_child.parent = p
node = p.left_child # 存储插入的节点
break
elif p.data < element: # 插入值大于节点,插入右子树
if p.right_child:
p = p.right_child
else:
p.right_child = BiTreeNode(element)
p.right_child.parent = p
node = p.right_child # 存储插入的节点
break
else:
# 等于的先不处理
return
# 二、调整balance_factor平衡因子
"""
1. 判断插入的节点是左子树还是右子树
1.1 左子树的话,balance_factor需要都减一
a. 插入节点的父节点bf < 0 -1 + -1 = -2 (需要进行调整)
b. 插入节点的父节点bf > 0 1 + -1 = 0
更新平衡因子直接返回
c. 插入节点的父节点bf = 0 0 + -1 = -1
等于-1表示插入节点的父节点右孩子还不是最小不平衡二叉排序树,需要进入父节点在旋转一次
更新平衡因子=-1
node = node.parent
1.2 右子树的话,balance_factor需要都加一
a. 插入节点的父节点bf < 0 -1 + 1 = 0
更新平衡因子直接返回
b. 插入节点的父节点bf > 0 1 + 1 = 2 (需要进行调整)
c. 插入节点的父节点bf = 0 0 + 1 = 1
等于-1表示插入节点的父节点右孩子还不是最小不平衡二叉排序树,需要进入父节点在旋转一次
更新平衡因子=-1
node = node.parent
"""
while node.parent:
if node.parent.left_child == node: # 插入的是左子树
if node.parent.bf < 0:
head = node.parent.parent # 插入节点的父节点的父节点,为了连接旋转之后的子树
temp = node.parent # 插入节点的父节点,旋转前的子树的根
if node.bf > 0:
n = self.LR(node.parent, node)
else:
n = self.RR(node.parent, node)
elif node.parent.bf > 0:
node.parent.bf = 0
break
else:
node.parent.bf = -1
node = node.parent
continue
else: # 插入的是右子树
if node.parent.bf > 0:
head = node.parent.parent # 插入节点的父节点的父节点
temp = node.parent # 插入节点的父节点
if node.bf < 0:
n = self.RL(node.parent, node)
else:
n = self.LL(node.parent, node)
elif node.parent.bf < 0:
node.parent.bf = 0
break
else:
node.parent.bf = 1
node = node.parent
continue
# 三、连接旋转后的子树
n.parent = head
if head:
if temp == head.left_child:
head.left_child = n
else:
head.right_child = n
break
else:
self.root = n
break
def mid_order(self, root):
"""中序遍历: 先处理左子树,之后是根,最后是右子树"""
if root:
self.mid_order(root.left_child) # 处理左子树
print(root.data, end=' ') # 处理根
self.mid_order(root.right_child) # 处理右子树
def back_order(self, root):
"""后序遍历:先处理左子树,之后是右子树,最后是根"""
if root:
self.back_order(root.left_child) # 处理左子树
self.back_order(root.right_child) # 处理右子树
print(root.data, end=' ') # 处理根
avl = AVLTree() # [3,2,1,6]
avl.insert_to_rec(3)
avl.insert_to_rec(2)
avl.insert_to_rec(1)
avl.insert_to_rec(6)
# avl.insert_to_rec(5)
# avl.insert_to_rec(1)
# avl.insert_to_rec(2)
avl.mid_order(avl.root)
print('\n')
avl.back_order(avl.root)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326