 url路由
url路由
# 对应脑图
# 链接资料
# 1. 概述
URL是Web服务的入口,用户通过浏览器发送过来的任何请求,都是发送到一个指定的URL地址,然后被响应。
URL路由在Django项目中的体现就是urls.py文件,这个文件可以有很多个,但绝对不会在同一目录下。实际上Django提倡项目有个根urls.py,各app下分别有自己的一个urls.py,既集中又分治,是一种解耦的模式。
随便新建一个Django项目,默认会自动为我们创建一个/project_name/urls.py文件,并且自动包含下面的内容,这就是项目的根URL:
from django.contrib import admin
from django.urls import path
urlpatterns = [
path('admin/', admin.site.urls),
]
2
3
4
5
6
# 1.1 d****jango如何处理请求****
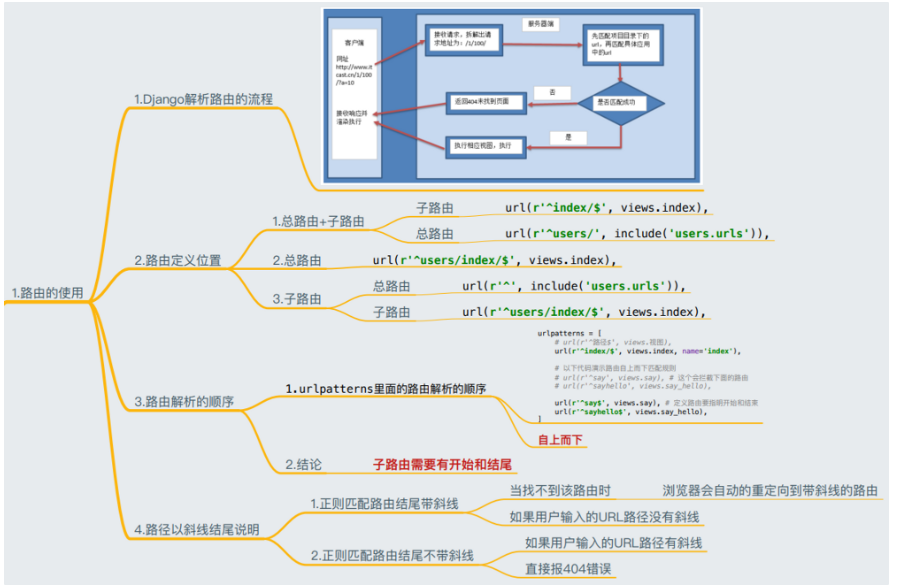
当用户请求一个页面时,Django根据下面的逻辑执行操作:
- **决定要使用的根URLconf模块。**通常,这是
ROOT_URLCONF设置的值,但是如果传入的HttpRequest对象具有urlconf属性(由中间件设置),则其值将被用于代替ROOT_URLCONF设置。也就是说你可以自定义项目入口url是哪个文件! - 加载该模块并寻找可用的urlpatterns。 它是
django.urls.path()或者django.urls.re_path()实例的一个列表。 - 依次匹配每个URL模式,在与请求的URL相匹配的第一个模式停下来。也就是说,url匹配是从上往下的短路操作,所以url在列表中的位置非常关键。
- 导入并调用匹配行中给定的视图,该视图是一个简单的Python函数(被称为视图函数),或基于类的视图。 视图将获得如下参数:
- 一个HttpRequest 实例。
- 如果匹配的表达式返回了未命名的组,那么匹配的内容将作为位置参数提供给视图。
- 关键字参数由表达式匹配的命名组组成,但是可以被
django.urls.path()的可选参数kwargs覆盖。 - 如果没有匹配到任何表达式,或者过程中抛出异常,将调用一个适当的错误处理视图。(比如403,比如无任何反应)
# 1.2 在settings.py配置,默认是否带/(APPEND_SLASH)
是否开启URL访问地址后面不为/跳转至带有/的路径的配置项
APPEND_SLASH=True #就是设置这个为False了django就不会默认加‘/’这个了
# 2. 路由
# 2.1 简单路由示例(url django1.x版本)
from django.conf.urls import url
urlpatterns = { #Django2.0了这里这是path,也可以在settings.py里面查看版本信息
url(正则表达式,views视图,参数,别名),
}
2
3
4
5
- 正则表达式:一个正则表达式字符串
- views视图:一个可调用对象,通常为一个视图函数
- 参数:可选的要传递给视图函数的默认参数(字典形式)
- 别名:一个可选的name参数
# 2.2 path转换器(path django 2.x-3.x版本)
from django.urls import path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<int:year>/', views.year_archive),
path('articles/<int:year>/<int:month>/', views.month_archive),
path('articles/<int:year>/<int:month>/<slug:slug>/', views.article_detail),
]
2
3
4
5
6
7
8
9
10
默认情况下,django内置下面的路径转换器:
str:匹配任何非空字符串,但不含斜杠/,如果你没有专门指定转换器,默认使用该转换器int:匹配0和正整数,返回一个int类型slug:可理解为注释、后缀、附属等概念,是url拖在最后的一部分解释性字符。该转换器匹配任何ASCII字符以及连接符和下划线,比如building-your-1st-django-site;uuid:匹配一个uuid格式的对象。为了防止冲突,规定必须使用破折号,所有字母必须小写,例如075194d3-6885-417e-a8a8-6c931e272f00。返回一个UUID对象;path:匹配任何非空字符串,重点是可以包含路径分隔符’/‘。这个转换器可以帮助你匹配整个url而不是一段一段的url字符串。要区分path转换器和path()方法。
注意:
- urlpatterns是个列表,每个元素都是
path()或re_path()的实例 - 要捕获一段url中的值,需要使用尖括号,而不是之前的圆括号;
- 可以转换捕获到的值为指定类型,比如例子中的int。默认情况下,捕获到的结果保存为字符串类型,不包含
/这个特殊字符; - 匹配模式的最开头不需要添加
/,因为默认情况下,每个url都带一个最前面的/,既然大家都有的部分,就不用浪费时间特别写一个了。 - 每个匹配模式都建议以斜杠结尾
# a. 匹配例子:
- /articles/2005/03/ 将匹配第三条,并调用`views.month_archive(request, year=2005, month=3)`;
- /articles/2003/匹配第一条,并调用`views.special_case_2003(request)`;
- /articles/2003将一条都匹配不上,因为它最后少了一个斜杠,而列表中的所有模式中都以斜杠结尾;
- /articles/2003/03/building-a-django-site/ 将匹配最后一个,并调用`views.article_detail(request, year=2003, month=3, slug="building-a-django-site"`
2
3
4
# b. 自定义path转换器
对于更复杂的匹配需求,你可能需要自定义你自己的path转换器。
path转换器其实就是一个类,包含下面的成员和属性:
- 类属性
regex:一个字符串形式的正则表达式属性; to_python(self, value)方法:一个用来将匹配到的字符串转换为你想要的那个数据类型,并传递给视图函数。如果转换失败,它必须弹出ValueError异常;to_url(self, value)方法:将Python数据类型转换为一段url的方法,上面方法的反向操作。如果转换失败,也会弹出ValueError异常。
例如,新建一个converters.py文件,与urlconf同目录,写个下面的类:
class FourDigitYearConverter:
regex = '[0-9]{4}'
def to_python(self, value):
return int(value)
def to_url(self, value):
return '%04d' % value
2
3
4
5
6
7
8
写完类后,在URLconf 中使用register_converter注册它,如下所示,注册了一个yyyy:
from django.urls import register_converter, path
from . import converters, views
register_converter(converters.FourDigitYearConverter, 'yyyy')
urlpatterns = [
path('articles/2003/', views.special_case_2003),
path('articles/<yyyy:year>/', views.year_archive),
...
]
2
3
4
5
6
7
8
9
10
11
# 2.3 正则表达式
r'^articles/2003/'
r:原生字符串
^:以什么开头
$:以什么结尾
\\d:数字 {}:几个数字范围 \\w:字母 [0-9][a-z] :0到9的数字和a到z的字符
. 匹配换行符之外的标志
+一个或多个
?0个或1个
*0个或多个
2
3
4
5
6
7
8
9
10
- urlpatterns中的元素按照书写顺序从上往下逐一匹配正则表达式,一旦匹配成功则不再继续。
- 若要从URL中捕获一个值,只需要在它周围放置一对圆括号(分组匹配)。
- 不需要添加一个前导的反斜杠,因为每个URL 都有。例如,应该是^articles 而不是 ^/articles。
- 每个正则表达式前面的'r' 是可选的但是建议加上。
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^blog/$', views.blog),
# blogs/2012/12/
url(r'^blogs/[0-9]{4}/\\d{2}/$', views.blogs), #如果不写$的时候,我们访问blog/2002就会被blog给截胡了,因为是从上向下查找的
url(r'^blogs/[0-9]{4}/$', views.blogs), # blogs/2012/
]
2
3
4
5
6
7
Django2.0的urlconf虽然改‘配置方式’了,但它依然向老版本兼容。而这个兼容的办法,就是用re_path()方法。re_path()方法在骨子里,根本就是以前的url()方法,只不过导入的位置变了。下面是一个例子,对比一下Django1.11时代的语法,有什么太大的差别?
from django.urls import path, re_path
from . import views
urlpatterns = [
path('articles/2003/', views.special_case_2003),
re_path(r'^articles/(?P<year>[0-9]{4})/$', views.year_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/$', views.month_archive),
re_path(r'^articles/(?P<year>[0-9]{4})/(?P<month>[0-9]{2})/(?P<slug>[\\w-]+)/$', views.article_detail),
]
2
3
4
5
6
7
8
9
10
与path()方法不同的在于三点:
- 捕获URL中的参数使用的是正则捕获,语法是
(?P<name>pattern),其中name是组名,pattern是要匹配的模式。 - year中匹配不到10000等非四位数字,这是正则表达式决定的
- 传递给视图的所有参数都是字符串类型。而不像
path()方法中可以指定转换成某种类型。在视图中接收参数时一定要小心。
# 2.4 *分组*
url地址上捕获的参数会按照 位置传参 方式传递给视图函数
位置传参:()
url(r'^blogs/([0-9]{4})/(\\d{2})/$', views.blogs),
url(r'^blogs/([0-9]{4})/$', views.blogs), # blogs/2012/
# views.py
def blogs(request,x,y): #一个括号,表示一个参数(位置传参),接送匹配到的数据
print(x,type(x))
print(y,type(y))
return HttpResponse("blogs")
2
3
4
5
6
7
8
9
# 2.5 *命名分组*
url地址上捕获的参数会按照 关键字传参 方式传递给视图函数
关键字传参:(?P<名称>) (?P<名称>)
url(r'^blogs/(?P<year>[0-9]{4})/(?P<month>\\d{2})/$', views.blogs),
def blogs(request,year,month): # 这里的名称一定要和关键字对应
print(year,type(year))
print(month,type(month))
return HttpResponse("blogs")
def blogs(request,*args,**kwargs): #元组,和字典,这样也可以
print(args)
print(kwargs)
2
3
4
5
6
7
8
9
10
11
分组和命名分组,不能混合用。捕获的参数永远都是字符串
# 2.6 *视图函数中指定默认值*
# urls.py中
urlpatterns = [
url(r'^blog/$', views.page), #没有捕获取到东西的话,将会使用默认值 num=1
url(r'^blog/page(?P<num>[0-9]+)/$', views.page),
]
# views.py中,可以为num指定默认值
def page(request, num="1"):
print(num)
pass;
2
3
4
5
6
7
8
9
10
在上面的例子中,两个URL模式指向相同的view - views.page - 但是第一个模式并没有从URL中捕获任何东西。
如果第一个模式匹配上了,page()函数将使用其默认参数num=“1”,如果第二个模式匹配,page()将使用正则表达式捕获到的num值。
# 2.7 *传递额外的参数给视图函数*
from django.urls import path
from . import views
urlpatterns = [
path('blog/<int:year>/', views.year_archive, {'foo': 'bar'}),
]
def year_archive(request,*args,**kwargs):
print(args) #('2012',)
print(kwargs) #{'k1': 'v1'}
return HttpResponse("blogs")
2
3
4
5
6
7
8
9
10
11
# 3. 路由分发
通常,我们会在每个app里,各自创建一个urls.py路由模块,然后从根路由出发,将app所属的url请求,全部转发到相应的urls.py模块中。
说明:在project下urls里面导入include包,然后只需要指向某个app就行了,然后具体app里面的,由他们自己设置
from django.contrib import admin
from django.urls import path,include #导入include
urlpatterns = [
path('admin/', admin.site.urls),
path('cmdb/',include("app01.urls")) #指向app0里面urls.py
]
2
3
4
5
6
7
8
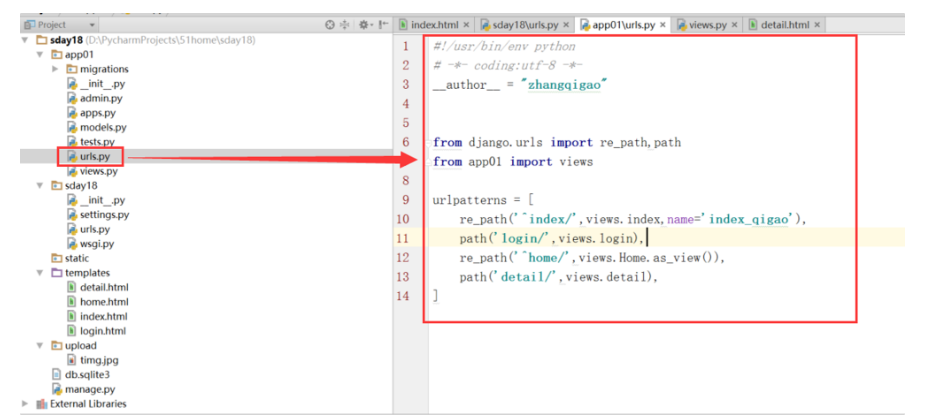
在app01的urls.py里面设置:
from django.urls import re_path,path
from app01 import views
urlpatterns = [
re_path('^index/',views.index,name='index_qigao'),
path('login/',views.login), #FBV的写法
re_path('^home/',views.Home.as_view()), #CBV的写法
path('detail/',views.detail),
]
2
3
4
5
6
7
8
9
如图:
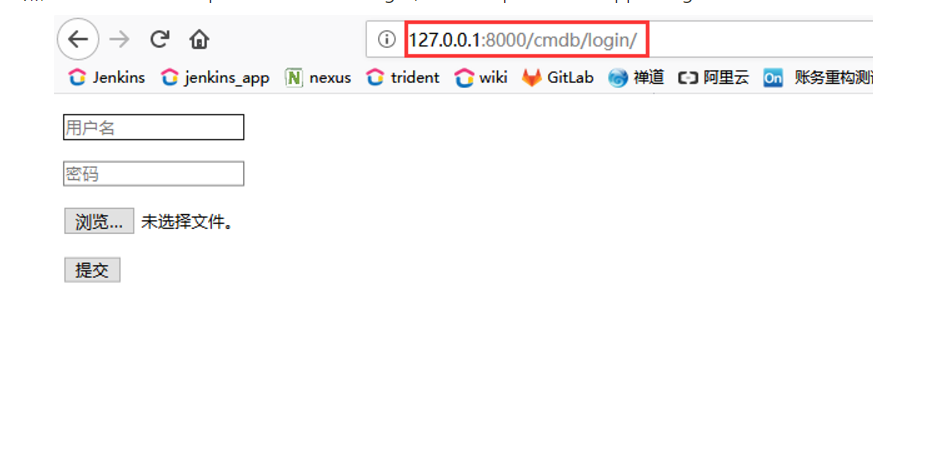
然后访问的时候:http:127.0.0.1/cmdb/login,就是 http:127.0.0.1/app名/login。如图:
# 3.1 *传递额外的参数给include()*
类似上面,也可以传递额外的参数给include()。参数会传递给include指向的urlconf中的每一行。
例如,下面两种URLconf配置方式在功能上完全相同:
配置一:
# main.py
from django.urls import include, path
urlpatterns = [
path('blog/', include('inner'), {'blog_id': 3}),
]
# inner.py
from django.urls import path
from mysite import views
urlpatterns = [
path('archive/', views.archive),
path('about/', views.about),
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
配置二:
# main.py
from django.urls import include, path
from mysite import views
urlpatterns = [
path('blog/', include('inner')),
]
# inner.py
from django.urls import path
urlpatterns = [
path('archive/', views.archive, {'blog_id': 3}),
path('about/', views.about, {'blog_id': 3}),
]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 4. *反向解析和命名空间*
# 4.1 *反向解析URL*
在需要解析URL的地方,对于不同层级,Django提供了不同的工具用于URL反查:
- 在模板语言中:使用
url模板标签。(也就是写前端网页时) - 在Python代码中:使用
reverse()函数。(也就是写视图函数等情况时) - 在更高层的与处理Django模型实例相关的代码中:使用
get_absolute_url()方法。(也就是在模型model中,参考前面的章节)
所有上面三种方式,都依赖于首先在path种为url添加name属性!
from django.urls import path
from . import views
urlpatterns = [
#...
path('articles/<int:year>/', views.year_archive, name='news-year-archive'),
#...
]
2
3
4
5
6
7
8
9
2020年对应的归档URL是/articles/2020/。
可以在模板的代码中使用下面的方法获得它们(可以结合模板语法章节来理解下面的内容):
<a href="{% url 'news-year-archive' 2020 %}">2020 Archive</a>
{# 或者使用for循环变量 #}
<ul>
{% for yearvar in year_list %}
<li><a href="{% url 'news-year-archive' yearvar %}">{{ yearvar }} Archive</a></li>
{% endfor %}
</ul>
2
3
4
5
6
7
8
其中,起到核心作用的是我们通过name='news-year-archive'为那条path起了一个可以被引用的名称。
URL名称name使用的字符串可以包含任何你喜欢的字符,但是过度的放纵有可能带来重名的冲突,比如两个不同的app,在各自的urlconf中为某一条path取了相同的name,这就会带来麻烦。为了解决这个问题,又引出了下面的命名空间。
# a. 静态路由
命名:name=""
url(r'^blogs/$', views.blogs, name="bloogs"), # 设置一个别名 bloogs
2
3
反向解析: 模板 生成的地址
<a href="{% url 'bloogs' %}">测试url的命名和反向解析</a> --> blogs - bloogs 获取的就是blogs
其实就是访问了别名为bloogs对应的url
2
py
from django.shortcuts import reverse #有两种导入的方法
from django.urls import reverse
print(reverse("bloogs")) #/blogs/
2
3
4
# b. 动态路由
- 分组:
url(r'^blogs/([0-9]{4})/(\\d{2})$', views.blogs, name="bloogs"),
反向解析:模板
<a href="{% url 'bloogs' '2002' '02' %}">测试url的命名和反向解析</a>
#要给上参数,还要参数对应,不然就会出错.其实就是访问了别名为bloogs对应的url
py
print(reverse("bloogs",args=(2002,99))) # /blogs/2002/99
2
3
4
5
6
7
8
- 命名分组
url(r'^blogs/(?P<year>[0-9]{4})/(?P<method>\\d{2})$', views.blogs, name="bloogs"),
反向解析:模板
{#<a href="{% url 'bloogs' '2002' '02' %}">测试url的命名和反向解析</a>#} #这个要对应参数
<a href="{% url 'bloogs' method='99' year='2000' %}">测试url的命名和反向解析</a> #这个不用对应参数
其实就是访问了别名为bloogs对应的url
py
print(reverse("bloogs",args=(2002,99))) # /blogs/2002/99
print(reverse("bloogs",kwargs={"year":"2009","method":99})) # /blogs/2009/9
2
3
4
5
6
7
8
9
10
# 4.2 *命名空间 namespace*
前面我们为介绍了path的name参数,为路由添加别名,实现反向url解析和软编码解耦。
但是,我们思考这么一个问题,假设下面的情况:
- appA,有一条路由A,它的name叫做
'index' - appB,有一条路由B,它的name也叫做
'index'
这种情况完全是有可能的,甚至还常见!
app01 urls.py:
urlpatterns = [
url(r'^home/$', views.home, name='home')
]
app02 urls.py:
urlpatterns = [
url(r'^home/$', views.home, name='home')
]
#app01和app02我们写了一样的别名
#我们用app01调用html的时候{% url 'home' %},app02的home会覆盖了app01里面的home
2
3
4
5
6
7
8
9
10
11
12
13
为了避免以上操作:我们就要加namespace
# 在项目的urls.py下
urlpatterns = [
url(r'^admin/', admin.site.urls),
url(r'^app01/', include("app01.urls", namespace="app01")),
url(r'^app02/', include("app02.urls", namespace="app02")),
]
2
3
4
5
6
光加了命名空间,也不行。我们在用反向解析和py的时候,也要在对应的地方区分并添加
反向解析:
模块
{% url 'app01:home' %}
{% url 'app02:home' %}
py
print(reverse("app01:home")) # /app01/home/
print(reverse("app02:home")) # /app02/home/
2
3
4
5
6
7
1