 复杂数据类型-字典
复杂数据类型-字典
# 字典
# 简介
Python (opens new window) 字典(dict)是一种无序的、可变的序列,它的元素以“键值对(key-value)”的形式存储。相对地,列表(list)和元组(tuple)都是有序的序列,它们的元素在底层是挨着存放的。
字典类型是 Python 中唯一的映射类型。“映射”是数学中的术语,简单理解,它指的是元素之间相互对应的关系,即通过一个元素,可以唯一找到另一个元素
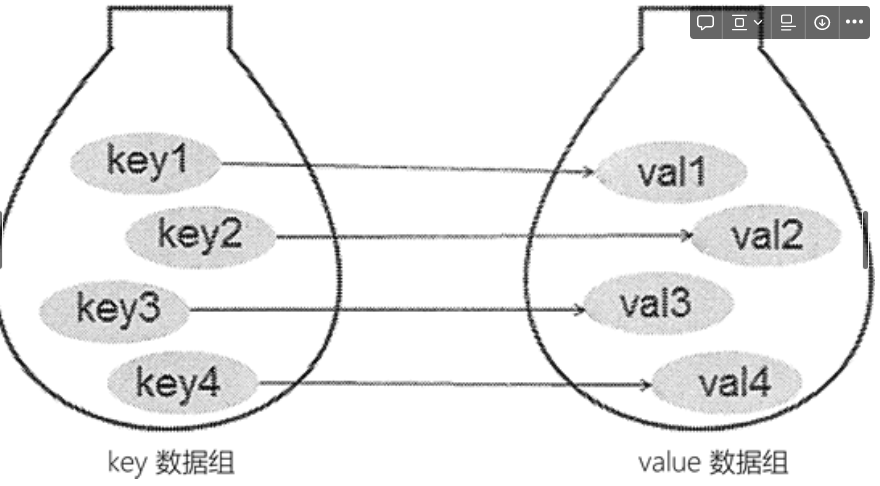
字典中,习惯将各元素对应的索引称为键(key),各个键对应的元素称为值(value),键及其关联的值称为“键值对”。
字典类型很像学生时代常用的新华字典。我们知道,通过新华字典中的音节表,可以快速找到想要查找的汉字。其中,字典里的音节表就相当于字典类型中的键,而键对应的汉字则相当于值。
字典的特点:
- 字典的key是唯一的【key不允许重复】
- key必须为不可变的数据(tuple,数据型,字符串,布尔值都是不可变的,可以被充当key)
- 通过键而不是通过索引来读取元素
- 字典是任意数据类型的无序集合
- 字典是可变的,并且可以任意嵌套
# 字典的创建/转换
# 创建
使用 { } 创建字典
# 使用{ }创建字典的语法格式如下: dictname = {'key':'value1', 'key2':'value2', ..., 'keyn':valuen}1
2通过 fromkeys() 方法创建字典
# 使用 dict 字典类型提供的 fromkeys() 方法创建带有默认值的字典 dictname = dict.fromkeys(list,value=None) knowledge = ['语文', '数学', '英语'] scores = dict.fromkeys(knowledge, 60) print(scores) # {'语文': 60, '英语': 60, '数学': 60} # 这种创建方式通常用于初始化字典,设置 value 的默认值。1
2
3
4
5
6
7通过 dict() 映射函数创建字典
# 创建空的字典 d = dict() print(d) # {}1
2
3通过setdefault() 方法创建字典
a = {'数学': 95, '语文': 89, '英语': 90} print(a) #key不存在,指定默认值 a.setdefault('物理', 94) print(a) #key不存在,不指定默认值 a.setdefault('化学') print(a) #key存在,指定默认值 a.setdefault('数学', 100) print(a) {'数学': 95, '语文': 89, '英语': 90} {'数学': 95, '语文': 89, '英语': 90, '物理': 94} {'数学': 95, '语文': 89, '英语': 90, '物理': 94, '化学': None} {'数学': 95, '语文': 89, '英语': 90, '物理': 94, '化学': None}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 转换
由于字典的每一个元素是键值对,所以想要转换为字典的必须要有个特定的格式才能转换成功
v = dict([("k1","v1"),("k2","v2")])
print(v) # 输出:{'k2': 'v2', 'k1': 'v1'}
v = dict([ ["k1","v1"], ["k2","v2"] ])
print(v) # 输出:{'k2': 'v2', 'k1': 'v1'}
# 子元素必须包含两个元素,从而将值对应给字典的键、值。
2
3
4
5
6
7
# 增
- 字典名[key] = value
# 注意:如果key存在,则表示修改value的值;如果key不存在,则表示在字典中添加一对新的键值对
dict1["abc"] = 20
print(dict1)
2
3
# *删*
- dict1.pop("key") 通过key删除
- dict1.popitem( ) 随机删除一个键值对,popitem() 总是弹出底层中的最后一个
- del dict1["key"] 通过key删除
- del dict1 删除整个字典
- dict1.clear() 清空字典里面的元素
注意:删除指定的key,对应的value也会随着删除
dict1.pop("lisi")
dict1.popitem()
dict1.clear() # 清空字典
del dict1['zhaoliu'] #删除key为zhaoliu的
del dict1 # 删除字典
print(dict1)
2
3
4
5
6
7
# 改
- 字典名[key] = value
- update() 方法
dict1 = {"zhaoliu": 1}
dict1["zhaoliu"] = 100 # key存在就是修改,不存在就是新增
result0 = dict1["zhaoliu"]
print(result0)
2
3
4
# update
在执行 update() 方法时,如果被更新的字典中己包含对应的键值对,那么原 value 会被覆盖;如果被更新的字典中不包含对应的键值对,则该键值对被添加进去。
a = {'one': 1, 'two': 2, 'three': 3}
a.update({'one':4.5, 'four': 9.3})
print(a) # {'one': 4.5, 'two': 2, 'three': 3, 'four': 9.3}
2
3
# 查
- 字典名["key"] 如果key不存在,则报错
- 字典名.get("key") 如果key不存在,返回None,不会报错
# 1.访问键值对
print(dict1["lisi"])
# 访问一个不存在的key,则报错
# print(dict1["abc"]) #KeyError: 'abc'
# 2.get()
result1 = dict1.get("zhaoliu")
print(result1)
# 如果key不存在,则不会报错,返回None,一般用于判断
result2 = dict1.get("def")
print(result2)
2
3
4
5
6
7
8
9
10
11
# 字典的遍历
直接遍历就是遍历的key
# 直接遍历key for key in dict1: print(key, dict1[key])1
2
3dict.values() 值
# 直接遍历value for value in dict1.values(): print(value)1
2
3enumerate(dict) 编号和key
# 遍历的是键值对的编号和key for i, element in enumerate(dict1): print(i, element)1
2
3dict.items() 同时遍历key和value
# 同时遍历key和value for key, value in dict1.items(): print(key, value)1
2
3keys() 方法用于返回字典中的所有键(key)列表
scores = {'数学': 95, '语文': 89, '英语': 90} print(scores.keys()) # dict_keys(['数学', '语文', '英语'])1
2values() 方法用于返回字典中所有键对应的值(value)列表
scores = {'数学': 95, '语文': 89, '英语': 90} print(scores.values()) # dict_values([95, 89, 90]) print(scores.items()) # dict_items([('数学', 95), ('语文', 89), ('英语', 90)])1
2
3同时循环两个或多个序列时,用
[zip(](<https://docs.python.org/zh-cn/3/library/functions.html#zip>))函数可以将其内的元素一一匹配>>> questions = ['name', 'quest', 'favorite color'] >>> answers = ['lancelot', 'the holy grail', 'blue'] >>> for q, a in zip(questions, answers): ... print('What is your {0}? It is {1}.'.format(q, a)) ... What is your name? It is lancelot. What is your quest? It is the holy grail. What is your favorite color? It is blue.1
2
3
4
5
6
7
8
# *面试题*
【面试题:dict和list之间的区别】
1.dict查找和插入的速度不会因为key-value的增多而变慢,
而list在每次查找的时候都是从头到尾进行遍历 ,当数据量大的时候,list速度肯定会变慢
2.dict需要占用大量的内存空间,内存浪费多,
而list只相当于存储了字典中的key或者value,并且list数据是紧密排列的
# 1.逐一显示列表l1 = ["Sun","Mon","Tue","Wed","Thu","Fri","Sat"]中索引为奇数的元素
l1 = ["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]
for i, index in enumerate(l1): # 方式一
if i % 2 != 0:
print(i, index)
for row in range(0, len(s), 2): # 方式二
print(row, s[row])
# 2.将属于列表l1 = ["Sun","Mon","Tue","Wed","Thu","Fri","Sat"],但不属于列表l2 = ["Sun","Mon","Thu","Fri","Sat"]的所有元素定义为一个新列表l3
l1 = ["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]
l2 = ["Sun", "Mon", "Thu", "Fri", "Sat"]
l3 = []
for i in l1:
if i not in l2: # 判断i不在l2中就添加到l3中
l3.append(i)
print(l3)
s = set(l1)
s1 = set(l2)
print(s ^ s1)
# 3.已知列表namelist=['stu1','stu2','stu3','stu4','stu5','stu6','stu7'],删除列表removelist=['stu3', 'stu7', 'stu9'];请将属于removelist列表中的每个元素从namelist中移除(属于removelist,但不属于namelist的忽略即可);
namelist = ['stu1', 'stu2', 'stu3', 'stu4', 'stu5', 'stu6', 'stu7']
removelist = ['stu3', 'stu7', 'stu9']
for i in removelist:
if i in namelist: # 在里面的话,就用remove()删除
namelist.remove(i)
print(namelist)
namelist = [i for i in namelist if i not in remove_set]
# 4.有一个字符串是一句英文,统计每个单词出现的次数,生成一个字典,单词作为key,次数作为value生成一个字典dict1
str1 = "today is a good day today is a bad day today is a nice day"
str2 = str1.split(" ") # 以空格分割,成列表
dict1 = {}
for i in str2:
c = dict1.get(i) # key:单词 value:次数 用.get()获取不到的话就为None(不会报错)
if c == None:
dict1[i] = 1 # 添加到字典
else:
dict1[i] += 1
print(dict1)
str2 = str1.split(" ")
dict1 = Counter(str2)
# 5.已知列表list1 = [0,1,2,3,4,5,6],list2 = ["Sun","Mon","Tue","Wed","Thu","Fri","Sat"],以list1中的元素作为key,list2中的元素作为value生成一个字典dict2
list1 = [0, 1, 2, 3, 4, 5, 6]
list2 = ["Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"]
dict2 = {k: v for k, v in zip(list1, list2)}
print(dict2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
1