 数据结构笔记(1)
数据结构笔记(1)
动图演示:
VISU算法 https://visualgo.net/zh/
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
下面图片地址:https://blog.csdn.net/ityqing/article/details/82838524
2
3
4
5
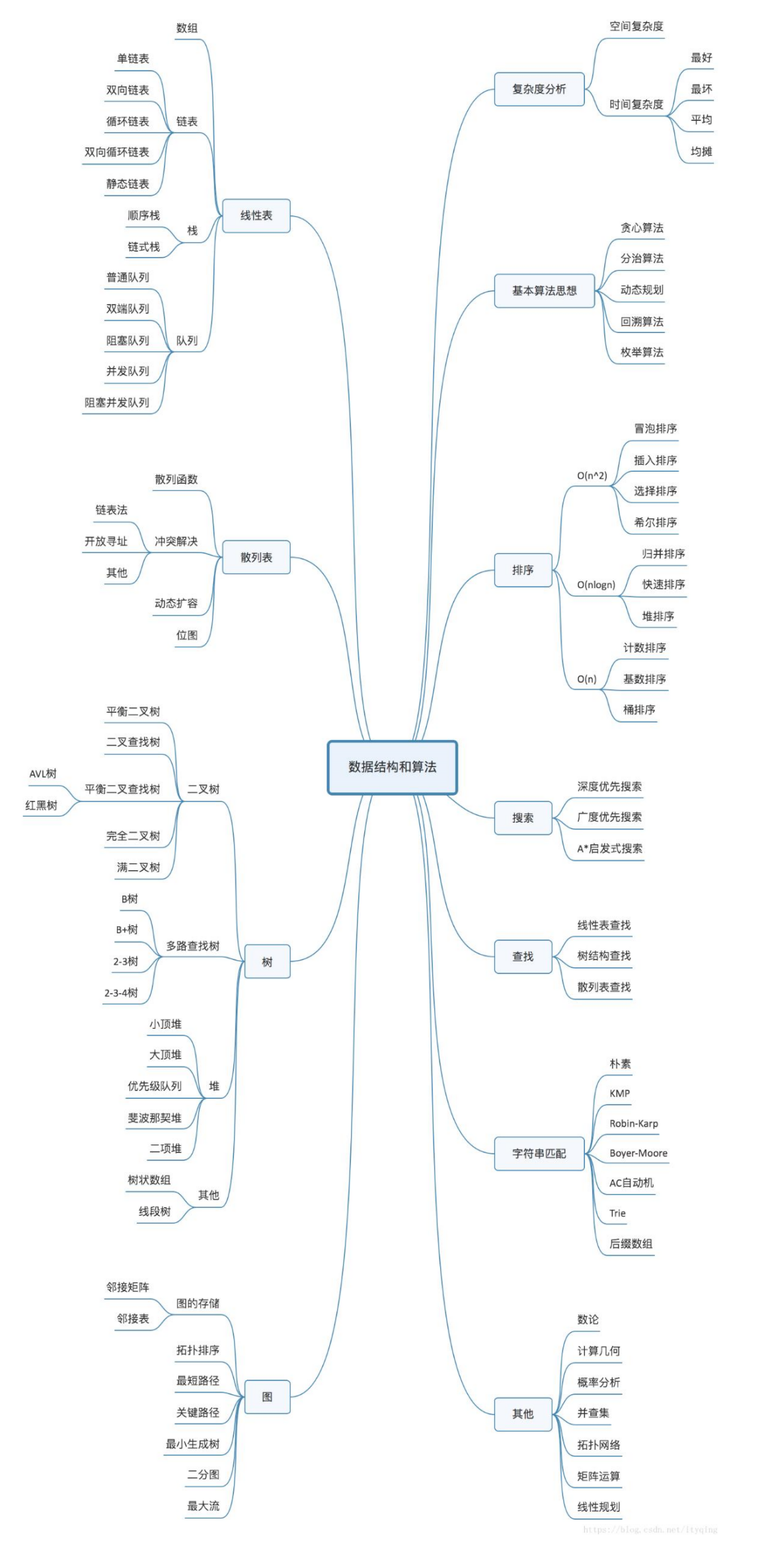
# 数据结构
数据结构介绍
https://www.yiibai.com/python/py_data_structure/python_data_structure_introduction.html
- 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成
- 简单来说,数据结构就是设计数据以何种方式组织并存储在计算
- python数据结构:列表、字典、集合、元组等都是一种数据结构
- N.WIRTH:"程序=数据结构+算法"
数据结构的分类
数据结构按照其逻辑结构可分成为线性结构、数结构、图结构
- 线性结构:数据结构中的元素存在一对一的相互关系
- 数结构:数据结构中的元素存在一对多的相互关系
- 图结构:数据结构中的元素存在多对多的相互关系
# 一、数据结构基础
博客园:https://www.cnblogs.com/feifeifeisir/p/13689770.html
python官网网站:https://docs.python.org/zh-cn/3/tutorial/datastructures.html#comparing-sequences-and-other-types
# 1. 列表
列表是Python中最基本的数据结构。列表中的每个元素都分配一个数字 表示它的下标或索引,从0开始
Python有6个序列的内置类型,但最常见的是列表和元组,包括前面所介绍的字符串。字符串是字符的序列,列表和元组则是任意python数据类型或对象的序列。
序列都可以进行的操作包括索引,切片,加,乘,检查成员。
此外,Python已经内置确定序列的长度以及确定最大和最小的元素的方法。
列表是最常用的Python数据类型,它可以作为一个方括号内的逗号分隔值出现。
列表的数据项不需要具有相同的类型
增删改查
- 列表是一种基本数据类型
- 关于列表的问题
- 列表中的元素是如何存储的? 存的是值的内存地址
- 列表的基本操作:按下标查找、插入元素、删除元素..
- 这些操作的时间复杂度是多少? O(1)
- 扩展:python的列表是如何实现的?
最显著的特征是:
- 列表中的每一个元素都是可变的;
- 列表中的元素是有序的,也就是说每一个元素都有一个位置;
- 列表可以容纳 Python 中的任何对象。
列表中的元素是可变的,这意味着我们可以在列表中添加、删除和修改元素。
# 2. 字典
# 3. 集合
# 4. 元组
# 二、栈
https://www.cainiaojc.com/note/qa3yo2.html
# 2.1 顺序栈
使用列表方法实现堆栈非常容易,最后插入的最先取出(“后进先出”)。把元素添加到堆栈的顶端,使用 append() 。从堆栈顶部取出元素,使用 pop() ,不用指定索引。
栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。
栈的特点:后进先出LIFO(last-in,first-out)
栈的概念:栈顶、栈底
栈的基本操作:
empty() – 返回栈是否为空 – Time Complexity : O(1) size() – 返回栈的长度 – Time Complexity : O(1) top() – 查看栈顶元素 – Time Complexity : O(1) push(g) – 向栈顶添加元素 – Time Complexity : O(1) pop() – 删除栈顶元素 – Time Complexity : O(1)1
2
3
4
5
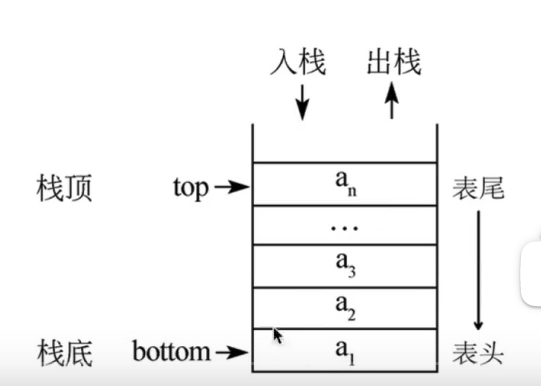
# 1. 顺序栈的基本操作
"""
使用列表方法实现堆栈非常容易,最后插入的最先取出(“后进先出”)。把元素添加到堆栈的顶端,使用 `append()` 。从堆栈顶部取出元素,使用 `pop()` ,不用指定索引。
- 栈(Stack)是一个数据集合,可以理解为只能在一端进行插入或删除操作的列表。
- 栈的特点:后进先出LIFO(last-in,first-out)
- 栈的概念:栈顶、栈底
- 栈的基本操作:
empty() – 返回栈是否为空 – Time Complexity : O(1)
size() – 返回栈的长度 – Time Complexity : O(1)
top() – 查看栈顶元素 – Time Complexity : O(1)
push(g) – 向栈顶添加元素 – Time Complexity : O(1)
pop() – 删除栈顶元素 – Time Complexity : O(1)
"""
class Stack(object):
def __init__(self):
self.stack = list() # 存放栈的列表
def push(self, element):
"""入栈"""
self.stack.append(element)
def pop(self):
"""出栈"""
if len(self.stack) > 0:
return self.stack.pop()
else:
return None
def top(self):
"""查看栈顶元素"""
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
def size(self):
"""栈长度"""
return len(self.stack)
def empty(self):
"""判断是否为空"""
return len(self.stack) == 0
def get_all(self):
"""获取全部元素"""
return self.stack
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.get_all())
print(stack.pop())
print(stack.top())
print(stack.empty())
"""
[1, 2, 3]
3
2
False
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
# 2. 顺序栈的实际应用
# 2.1 括号匹配问题
- 括号匹配问题:给一个字符串,其中包含小括号、中括号、大括号,求改字符串中的括号是否匹配。
- 例如:
- ()()[]{} 匹配
- [{}{()}] 匹配
- []{ 不匹配
思路:
由于只检查()是否平衡,比较简单
思路是,
遇到( 则将( 进栈
遇到 )则将当前栈顶的( 出栈
如果是这两个符号以外的其他字符
,则不执行任何操作
如果:
在执行 )出栈的时候,栈已经为空,则表示符号不平衡【说明 )更多】
在执行完所有的出栈后,栈不为空,则符号也不平衡【说明( 更多】
2
3
4
5
6
7
8
9
10
"""
- 括号匹配问题:给一个字符串,其中包含小括号、中括号、大括号,求改字符串中的括号是否匹配。
- 例如:
- ()()[]{} 匹配
- [{}{()}] 匹配
- []{ 不匹配
利用栈实现
思路:
由于只检查()是否平衡,比较简单
思路是,
遇到( 则将( 进栈
遇到 )则将当前栈顶的( 出栈
如果是这两个符号以外的其他字符,则不执行任何操作
如果:
在执行 )出栈的时候,栈已经为空,则表示符号不平衡【说明 )更多】
在执行完所有的出栈后,栈不为空,则符号也不平衡【说明( 更多】
"""
class Stack(object):
def __init__(self):
self.stack = [] # 存放栈的列表
def push(self, element):
"""入栈"""
self.stack.append(element)
def pop(self):
"""出栈"""
if len(self.stack) > 0:
return self.stack.pop()
else:
return None
def get_top(self):
"""查看栈顶元素"""
if len(self.stack) > 0:
return self.stack[-1]
else:
return None
def is_empty(self):
"""判断栈是否为空"""
return len(self.stack) == 0
def brace_math(s):
"""
:param s: 给定字符串
:return:
"""
match = {'}': '{', ')': '(', ']': '['}
stack = Stack()
brackets = {'{', '(', '['}
for element in s:
if element in brackets:
stack.push(element)
else:
if stack.is_empty():
return False
elif stack.get_top() == match[element]:
stack.pop()
else:
return False
return stack.is_empty()
# print(brace_math('{"a":{"b":1}}'))
print(brace_math('()()[]{}'))
print(brace_math('[{}{()}]'))
print(brace_math('{(})}'))
print(brace_math('[]{'))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
# 2.2 最长有效括号
给你一个只包含 '('和 ')'的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
示例 2:
输入:s = ")()())" ()()都是正确的
输出:4
解释:最长有效括号子串是 "()()"
示例 3:
输入:s = ""
输出:0
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
"""
给你一个只包含 '('和 ')'的字符串,找出最长有效(格式正确且连续)括号子串的长度。
示例 1:
输入:s = "(()"
输出:2
解释:最长有效括号子串是 "()"
示例 2:
输入:s = ")()())" ()()都是正确的
输出:4
解释:最长有效括号子串是 "()()"
示例 3:
输入:s = ""
输出:0
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/longest-valid-parentheses
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
"""
def longestValidParentheses(s: str) -> int:
"""动态规划"""
length = len(s)
if length == 0:
return 0
dp = [0] * length
for i in range(1, length):
# 当遇到右括号时,尝试向前匹配左括号
if s[i] == ')':
pre = i - dp[i - 1] - 1
# 如果是左括号,则更新匹配长度
if pre >= 0 and s[pre] == '(':
dp[i] = dp[i - 1] + 2
# 处理独立的括号对的情形 类似()()、()(())
if pre > 0:
dp[i] += dp[pre - 1]
return max(dp)
# print(longestValidParentheses("()()(()"))
def longestValidParentheses2(s: str) -> int:
"""栈
具体做法是我们始终保持栈底元素为当前已经遍历过的元素中「最后一个没有被匹配的右括号的下标」,
这样的做法主要是考虑了边界条件的处理,栈里其他元素维护左括号的下标:
对于遇到的每个 \text{‘(’}‘(’ ,我们将它的下标放入栈中
对于遇到的每个 \text{‘)’}‘)’ ,我们先弹出栈顶元素表示匹配了当前右括号:
如果栈为空,说明当前的右括号为没有被匹配的右括号,我们将其下标放入栈中来更新我们之前提到的「最后一个没有被匹配的右括号的下标」
如果栈不为空,当前右括号的下标减去栈顶元素即为「以该右括号为结尾的最长有效括号的长度」
我们从前往后遍历字符串并更新答案即可。
需要注意的是,如果一开始栈为空,第一个字符为左括号的时候我们会将其放入栈中,这样就不满足提及的「最后一个没有被匹配的右括号的下标」,
为了保持统一,我们在一开始的时候往栈中放入一个值为 -1−1 的元素
"""
stack = [-1]
length = 0
max_length = 0
for i in range(len(s)):
if s[i] == '(':
stack.append(i) # 记录下标
else:
stack.pop()
if not stack:
stack.append(i)
else:
length = i - stack[-1]
max_length = max(max_length, length)
return max_length
print(longestValidParentheses2("()()(()"))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
# 2.3 迷宫问题
"""
栈--深度有限搜索(栈实现)
- 回溯法 到找不到的时候,会上一个节点继续上下左右的找,一直回退到可以走的点
- 思路:**从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其它方法的点**(只有上下左右,不能斜着走)
- 使用栈储存当前路径
"""
2
3
4
5
6
"""
2. 栈--深度有限搜索(栈实现)
- 回溯法 到找不到的时候,会上一个节点继续上下左右的找,一直回退到可以走的点
- 思路:**从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其它方法的点**(只有上下左右,不能斜着走)
- 使用栈储存当前路径
"""
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
] # 迷宫地图: 1表示障碍点(墙) 0表示可以通行的点
dirs = [
lambda x, y: (x + 1, y), # 向下走
lambda x, y: (x - 1, y), # 向上走
lambda x, y: (x, y + 1), # 向右走
lambda x, y: (x, y - 1), # 向左走
]
def maze_path(x1, y1, x2, y2):
"""
:param x1: 起点x轴
:param y1: 起点y轴(x1,y1)
:param x2: 终点x轴
:param y2: 终点y轴(x2,y2)
:return:
"""
stack = [(x1, y1)] # 存放路径的列表(先将起点添加到路径中)
while len(stack) > 0:
current_position = stack[-1] # 当前位置(列表最后一个就是走的当前位置)
if current_position[0] == x2 and current_position[1] == y2:
"""表示已经走到终点"""
for p in stack: # 遍历走的路线
print(p,end=" ")
return True
for item in dirs:
next_node = item(current_position[0], current_position[1]) # 下一个点
if maze[next_node[0]][next_node[1]] == 0: # 如果下一个点可以通行,添加到栈中
stack.append(next_node)
maze[next_node[0]][next_node[1]] = 2 # 将走过的点赋值为2
break
# 表示上下左右没有点可以走,就回退点,如果没有继续回退(并删除栈中的内容)
else:
maze[current_position[0]][current_position[1]] = 2
stack.pop()
else:
# 表示没有找到通道,
print('没有找到通道')
return False
print(maze_path(1, 1, 8, 8))
"""
(1, 1) (2, 1) (3, 1) (4, 1) (5, 1) (5, 2) (5, 3) (6, 3) (6, 4) (6, 5) (7, 5) (8, 5) (8, 6) (8, 7) (8, 8) True
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
# 2.2 链式栈
链栈的实现思路同顺序栈类似,顺序栈是将顺序表(数组)的一端作为栈低,另一端为栈顶;链栈也如此,通常我们将链表的头部作为栈顶,尾部作为栈低

将链表头部作为栈顶的一端,可以避免在实现数据"入栈"和"出栈"操作时做大量遍历链表的耗时操作。
链表的头部作为栈顶,意味着:
在实现数据入栈操作时,需要将数据从链表的头部插入;
在实现数据出栈操作时,需要删除链表头部的首节点;
基本操作:
因此,**链栈实际上就是一个只能采用头插插入或删除数据的链表**。 empty() – 返回栈是否为空 – 判断链表是否为空 size() – 返回栈的长度 – 遍历链表 top() – 查看栈顶元素 – 查看链表的第一个元素 push(g) – 向栈顶添加元素 – 头插法 pop() – 删除栈顶元素 – 删除第一个元素1
2
3
4
5
6
7
# 1. 链式栈的基本操作
"""
**将链表头部作为栈顶的一端,可以避免在实现数据"入栈"和"出栈"操作时做大量遍历链表的耗时操作。**
链表的头部作为栈顶,意味着:
- 在实现数据入栈操作时,需要将数据从链表的头部插入;
- 在实现数据出栈操作时,需要删除链表头部的首节点;
- 基本操作:
因此,**链栈实际上就是一个只能采用头插插入或删除数据的链表**。
empty() – 返回栈是否为空 – 判断链表是否为空
size() – 返回栈的长度 – 遍历链表
top() – 查看栈顶元素 – 查看链表的第一个元素
push(g) – 向栈顶添加元素 – 头插法
pop() – 删除栈顶元素 – 删除第一个元素
"""
# 多个节点连接在一起变成了一条链条
class Node(object):
"""节点"""
def __init__(self, data):
self.data = data # 当前节点的值
self.next = None # 当前节点的下一个节点
class Stack(object):
def __init__(self):
self.head = None # 链表,存放节点
def push(self, element):
"""入栈: 头插法"""
node = Node(element)
if self.head is None:
self.head = node
else:
node.next = self.head # 新节点的next 直接添加链条
self.head = node
def pop(self):
"""出栈: 删除链表第一个元素"""
if self.head is None:
raise IndexError('链表为空')
remove_node = self.head.data
self.head = self.head.next
return remove_node
def top(self):
"""查看栈顶元素"""
if self.head is None:
return None
return self.head.data
def size(self):
"""栈长度"""
if self.head is None:
return 0
head_node = self.head
count = 0
while head_node is not None:
count += 1
head_node = head_node.next
return count
def empty(self):
"""判断是否为空"""
return self.head is None
def get_all(self):
"""获取全部元素"""
if self.head is None:
return None
head_node = self.head
while head_node is not None:
print(head_node.data, end=' ')
head_node = head_node.next
stack = Stack()
stack.push(1)
stack.push(2)
stack.push(3)
print(stack.get_all())
print(stack.pop())
print(stack.top())
print(stack.empty())
print('栈长度: ', stack.size())
print(stack.get_all())
"""
3 2 1 None
3
2
False
栈长度: 2
2 1 None
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
# 2. 链式栈的实际应用
# 2.1 数制转换
十进制数N和其他d进制数的转换是计算机实现计算的基本问题,其解决方法很多,其中一个简单算法基于下列原理:
N = (N div d) * d + N mod d(其中:div为整除运算,mod为求余运算)
例如:将十进制的121转化为二进制的过程为:
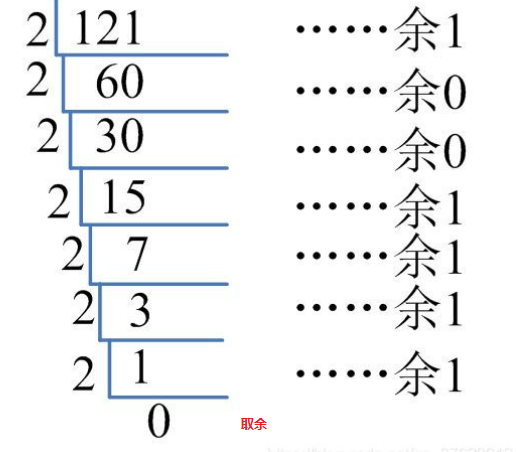
"""
十进制数N和其他d进制数的转换是计算机实现计算的基本问题,其解决方法很多,其中一个简单算法基于下列原理:
N = (N div d) * d + N mod d(其中:div为整除运算,mod为求余运算)
将十进制的121转化为二进制的过程为:
"""
class Node(object):
"""节点"""
def __init__(self, data):
self.data = data
self.next = None
class Stack(object):
def __init__(self):
self.head = None # 链表,存放节点
def push(self, element):
"""入栈: 头插法"""
node = Node(element)
if self.head is None:
self.head = node
return
node.next = self.head
self.head = node
def tail(self, element):
"""尾插法"""
node = Node(element)
if self.empty():
self.head = node
return
head_node = self.head
while head_node.next is not None:
head_node = head_node.next
head_node.next = node
def pop(self):
"""出栈: 删除链表第一个元素"""
if self.head is None:
raise IndexError('链表为空')
remove_node = self.head.data
self.head = self.head.next
return remove_node
def top(self):
"""查看栈顶元素"""
if self.head is None:
return None
return self.head.data
def size(self):
"""栈长度"""
if self.head is None:
return 0
head_node = self.head
count = 0
while head_node is not None:
count += 1
head_node = head_node.next
return count
def empty(self):
"""判断是否为空"""
return self.head is None
def get_all(self):
"""获取全部元素"""
if self.head is None:
return None
head_node = self.head
while head_node is not None:
print(head_node.data, end=' ')
head_node = head_node.next
def digital_conversion(num):
"""十进制转二进制"""
stack = Stack()
while num != 0:
stack.tail(num % 2)
num = num // 2
return stack.get_all()
print(digital_conversion(121))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
# Leetcode 练习
https://leetcode.com/problems/implement-queue-using-stacks/
# 三、队列
# 3.1 普通队列
# 1. 单向队列
python实现队列模块(刘江):https://www.liujiangblog.com/course/python/59
python实现队列模块:https://docs.python.org/zh-cn/3/library/queue.html
2
先进先出队列,类似管道。元素只能从队头方向一个一个的弹出,只能从队尾一个一个的放入。
- 队列(Queue)是一个数据集合,仅允许在列表的一端进行插入,另一段进行删除
- 进行插入的一端称为队尾(rear),插入动作称为进队或入队
- 进行删除的一端称为对头(front),删除动作称为出队
- 队列的性质:先进先出(First-in,First-out)

队列能否用列表简单实现?为什么?
不能用列表实现,因为出队的时候是删除列表的第一个元素,这样会导致后面的元素都会向前面移动一位,太慢了(!所有可以内部操作的时候把入队和出队反过来,)
解决方法:在内部将列表反过来入队从前面入队,出队从后面出队,就避免了上面的问题
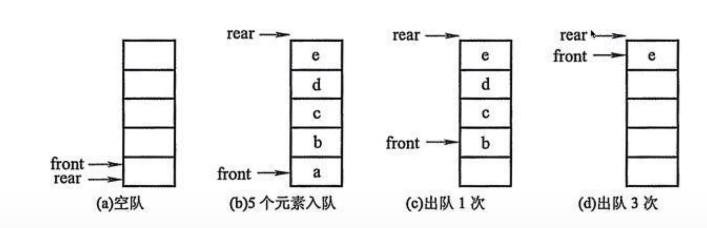
"""
队列:先进先出
push(): 入队: 在头部添加成员
pop(): 出队: 在尾部添加成员 ! 因为不能从列表的头部开始删除,会导致后面的元素都向前移动一位,会很慢。所有这里把出队入队反过来了
top(): 返回队列的头部成员
is_Empty(): 检测队列是否为空,若为空,则返回True,否则返回False
length(): 返回队列的成员数量
travel(): 遍历队列所有成员
"""
class Queue(object):
def __init__(self):
self.queue = [] # 队列
def push(self, element):
"""入队"""
self.queue.insert(0, element)
def pop(self):
"""出队"""
if not self.queue:
return None
return self.queue.pop()
def top(self):
"""返回头部元素"""
if not self.queue:
return None
return self.queue[-1]
def is_empty(self):
"""校验队列是否为空"""
return self.queue == []
def length(self):
"""返回队列长度"""
return len(self.queue)
def travel(self):
"""遍历队列"""
if not self.queue:
return None
return self.queue[::-1]
queue = Queue()
queue.push(1)
queue.push(2)
print(queue.top())
print(queue.is_empty())
print(queue.length())
print(queue.travel())
"""
1
False
2
[1, 2]
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 2. 环形队列
对于循环队列,我们需要定义一个变量(front)指向队首,同样需要定义(rear)指向下一个元素入队的位置
- 环形队列:当队尾指针front == Maxsize(最大存放多少) + 1时,在前进一个位置就自动到0
- 队首指针前进1:front = (front + 1) % MaxSize
- 队尾指针前进1:rear = (rear + 1) % MaxSize
- 队空条件:rear == front
- 队满条件:(rear + 1) % MaxSize == front
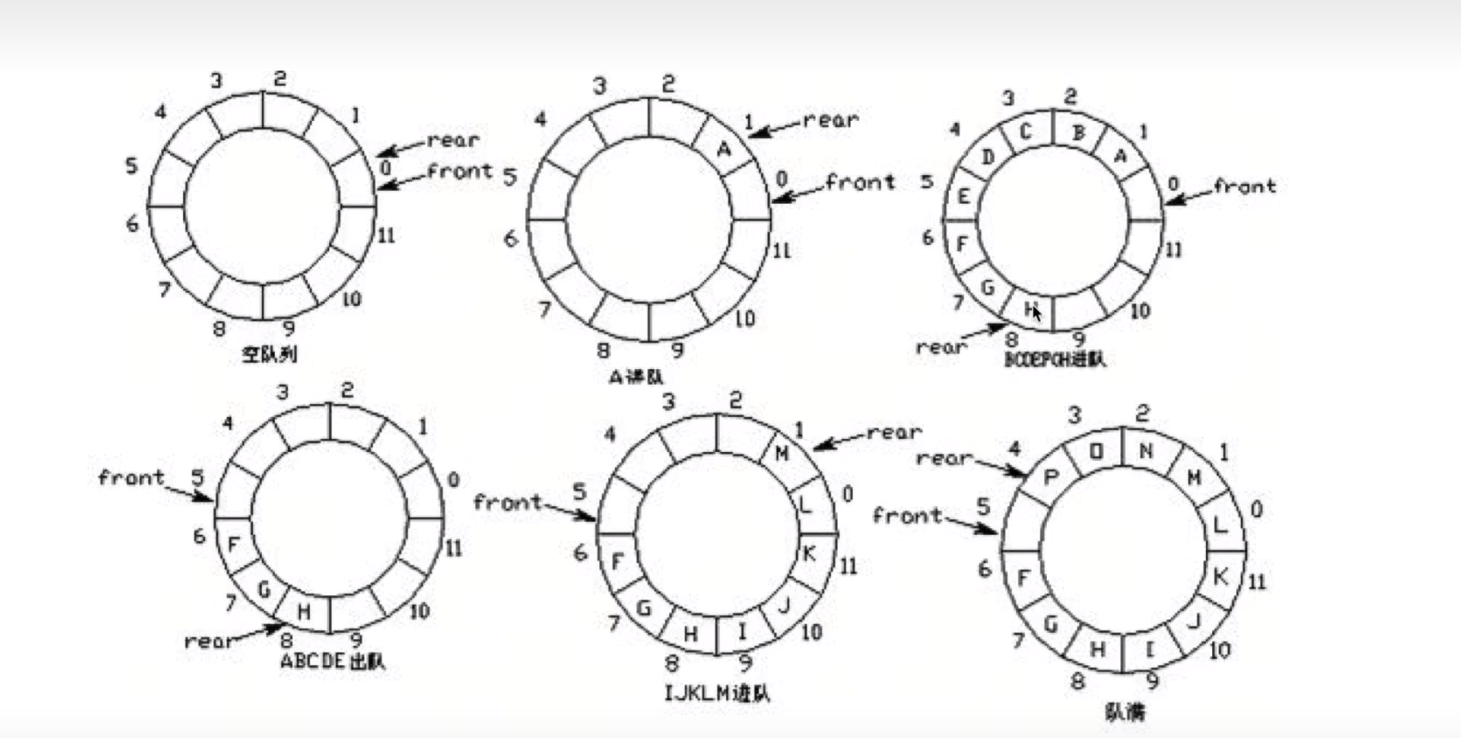
环形队列的基本实现原理
"""
环形队列:当队尾指针front == Maxsize(最大存放多少) + 1时,在前进一个位置就自动到0
- 队首指针前进1:front = (front + 1) % MaxSize
- 队尾指针前进1:rear = (rear + 1) % MaxSize
- 队空条件:rear == front
- 队满条件:(rear + 1) % MaxSize == front
环形队列,把队首队尾,连接起来
"""
class Queue(object):
def __init__(self, size):
# 不加一的话,会空出来一个0号位置(或者直接从0下标进行添加元素)
self.queue = [0 for _ in range(size)] # 创建队列[_,_...]
self.size = size
self.front = 0 # 队首,用于出队
self.rear = 0 # 队尾,用户与入队
def push(self, element):
"""入队"""
if not self.is_filled():
self.rear = (self.rear + 1) % self.size
self.queue[self.rear] = element
else:
raise IndexError('队列已满')
def pop(self):
"""出队"""
if not self.is_empty():
self.front = (self.front + 1) % self.size
return self.queue[self.front]
else:
raise IndexError('队列为空')
def is_empty(self):
"""判断队列是否为空"""
return self.rear == self.front
def is_filled(self):
"""判断队列是否已满"""
return (self.rear + 1) % self.size == self.front
q = Queue(3)
q.push(1)
q.push(2)
print(q.is_filled())
print(q.pop())
print(q.pop())
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
# 3. 普通队列的实际应用
# 3.1 实现读取文件的第n行
from collections import deque
# 小示例: 实现读取文件的第n行
def tail(n):
"""读取n行文件"""
with open('a.txt', 'rb') as f:
q = deque(f, n)
return q # 返回第n行
for row in tail(6):
print(row)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 3.2 双端队列
# 双向队列(内置模块deque)
https://docs.python.org/zh-cn/3/library/collections.html?highlight=deque#collections.deque
- 双向队列的两端都支持进队和出队的操作
- 双向队列的基本操作
- 队首进队
- 队首出队
- 队尾进队
- 队尾出队
"""
双向队列(deque)对象支持以下方法:
append(x)
添加 x 到右端。
appendleft(x)
添加 x 到左端。
clear()
移除所有元素,使其长度为0.
copy()
创建一份浅拷贝。
3.5 新版功能.
count(x)
计算 deque 中元素等于 x 的个数。
3.2 新版功能.
extend(iterable)
扩展deque的右侧,通过添加iterable参数中的元素。
extendleft(iterable)
扩展deque的左侧,通过添加iterable参数中的元素。注意,左添加时,在结果中iterable参数中的顺序将被反过来添加。
index(x[, start[, stop]])
返回 x 在 deque 中的位置(在索引 start 之后,索引 stop 之前)。 返回第一个匹配项,如果未找到则引发 ValueError。
3.5 新版功能.
insert(i, x)
在位置 i 插入 x 。
如果插入会导致一个限长 deque 超出长度 maxlen 的话,就引发一个 IndexError。
3.5 新版功能.
pop()
移去并且返回一个元素,deque 最右侧的那一个。 如果没有元素的话,就引发一个 IndexError。
popleft()
移去并且返回一个元素,deque 最左侧的那一个。 如果没有元素的话,就引发 IndexError。
remove(value)
移除找到的第一个 value。 如果没有的话就引发 ValueError。
reverse()
将deque逆序排列。返回 None 。
3.2 新版功能.
rotate(n=1)
向右循环移动 n 步。 如果 n 是负数,就向左循环。
如果deque不是空的,向右循环移动一步就等价于 d.appendleft(d.pop()) , 向左循环一步就等价于 d.append(d.popleft()) 。
Deque对象同样提供了一个只读属性:
maxlen
Deque的最大尺寸,如果没有限定的话就是 None 。
"""
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
# 3.3 阻塞队列
# 3.4 并发队列
# 3.5 阻塞并发队列
# Python四种类型的队例:
https://www.jianshu.com/p/6acf82c84fc5
Queue:FIFO 即first in first out 先进先出LifoQueue:LIFO 即last in first out 后进先出PriorityQueue:优先队列,级别越低,越优先deque:双边队列
# 栈和队列的引用--迷宫问题
https://www.cnblogs.com/xiugeng/p/9687354.html
给一个二维列表,表示迷宫(0表示通道,1表示围墙)。给出算法,求一条走出迷宫的路径

# 栈--深度优先搜索(栈实现)
- 回溯法
- 思路:从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其它方法的点(只有上下左右,不能斜着走)
- 使用栈储存当前路径
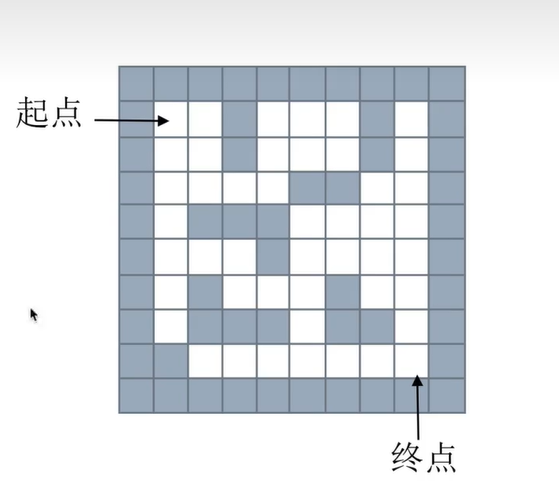
"""
栈--深度有限搜索(栈实现)
- 回溯法 到找不到的时候,会上一个节点继续上下左右的找,一直回退到可以走的点
- 思路:**从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其它方法的点**(只有上下左右,不能斜着走)
- 使用栈储存当前路径
"""
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
] # 迷宫地图: 1表示障碍点(墙) 0表示可以通行的点
dirs = [
lambda x, y: (x + 1, y), # 向下走
lambda x, y: (x - 1, y), # 向上走
lambda x, y: (x, y + 1), # 向右走
lambda x, y: (x, y - 1), # 向左走
]
def maze_path(x1, y1, x2, y2):
"""
:param x1: 起点x轴
:param y1: 起点y轴(x1,y1)
:param x2: 终点x轴
:param y2: 终点y轴(x2,y2)
:return:
"""
stack = [(x1, y1)] # 存放路径的列表(先将起点添加到路径中)
while len(stack) > 0:
current_position = stack[-1] # 当前位置(列表最后一个就是走的当前位置)
if current_position[0] == x2 and current_position[1] == y2:
"""表示已经走到终点"""
for p in stack:
print(p)
return True
for item in dirs:
next_node = item(current_position[0], current_position[1]) # 下一个点
if maze[next_node[0]][next_node[1]] == 0: # 如果下一个点可以通行,添加到栈中
stack.append(next_node)
maze[next_node[0]][next_node[1]] = 2 # 将走过的点赋值为2
break
# 表示上下左右没有点可以走,就回退点,如果没有继续回退(并删除栈中的内容)
else:
maze[next_node[0]][next_node[1]] = 2
stack.pop()
else:
# 表示没有找到通道,
print('没有找到通道')
return False
print(maze_path(1, 1, 8, 8))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
# 队列--广度优先搜索
队列求解算法中,以队列存储可以探索的位置。利用队列先进先出的特点,实现在每个分支上同时进行搜索路径,直到找到出口。这是一种广度优先搜索的方法。
思路:从一个节点开始,寻找所有接下来能继续走的点,继续不断寻找,直到找到出口
使用队列存储当前正在考虑的节点
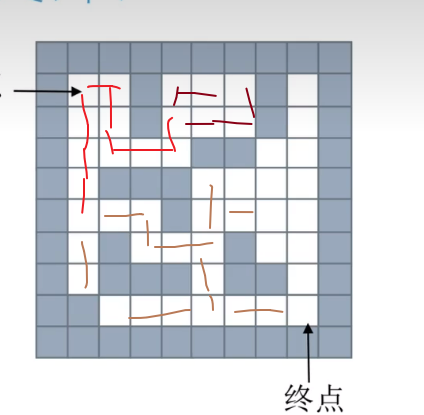
"""
栈--深度有限搜索(栈实现)
- 回溯法 到找不到的时候,会上一个节点继续上下左右的找,一直回退到可以走的点
- 思路:**从一个节点开始,任意找下一个能走的点,当找不到能走的点时,退回上一个点寻找是否有其它方法的点**(只有上下左右,不能斜着走)
- 使用栈储存当前路径
"""
from collections import deque
maze = [
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 0, 1, 0, 1],
[1, 0, 0, 0, 0, 1, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 1, 0, 0, 0, 1, 0, 0, 1],
[1, 0, 1, 1, 1, 0, 1, 1, 0, 1],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
] # 迷宫地图: 1表示障碍点(墙) 0表示可以通行的点
dirs = [
lambda x, y: (x + 1, y), # 向下走
lambda x, y: (x - 1, y), # 向上走
lambda x, y: (x, y + 1), # 向右走
lambda x, y: (x, y - 1), # 向左走
]
def print_r(path):
"""
输出路径
:param path: 存放路径的列表
:return:
"""
# print(11111,path)
current_position = path[-1] # 随便记录一个当前点
path_list = [] # 去掉下标的路径
while current_position[2] != -1: # 当前点是起点时开始向路径中添加信息,循环
path_list.append(current_position[0:2])
current_position = path[current_position[2]]
print(path_list)
path_list.append(current_position[0:2])
path_list.reverse()
for item in path_list:
print(item)
# return True
def maze_path_queue(x1, y1, x2, y2):
"""
:param x1: 起点x轴
:param y1: 起点y轴(x1,y1)
:param x2: 终点x轴
:param y2: 终点y轴(x2,y2)
:return:
"""
# 1、创建队列:记录配置走的通道(x,y,下标)
queue = deque()
queue.append((x1, y1, -1)) # 记录启动位置,-1表示的是起点的下标,当走一步下标加1
path = [] # 记录所走的路径
while len(queue) > 0:
current_position = queue.pop() # 队列的最后一个表示是当前所在位置
path.append(current_position) # 将当前点添加到path中
if current_position[0] == x2 and current_position[1] == y2:
"""表示找到出口,打印路径"""
print_r(path)
return True
for item in dirs: # 如果下面没有点要走,就会重新执行while循环并退回上一个点进行寻找
next_node = item(current_position[0], current_position[1]) # 下一个走的点
if maze[next_node[0]][next_node[1]] == 0: # 下一个等于0表示可以通行,将点添加到队列中,并len(path)-1记录位置
queue.append((next_node[0], next_node[1], len(path) - 1)) # 将当前点的下一个点添加到path中
maze[next_node[0]][next_node[1]] = 2 # 将走过的点标记成2
else:
print('没有出口')
return False
print(maze_path_queue(1, 1, 8, 8))
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84